10 types of data for your keyword clustering wish list – 10 types of data for your clustering wish list: This post dives deep into the essential data types needed for effective clustering. We’ll explore various data types, from simple search volume to complex user behavior patterns, and explain how each contributes to creating insightful clusters. Understanding these data types is crucial for creating a successful clustering strategy, especially in today’s digital landscape.
We’ll cover everything from defining data types and quality considerations to clustering methods, data representation, and performance evaluation. We’ll also explore real-world applications, visualization techniques, and strategies for selecting the right data types for your specific needs. Finally, we’ll examine data handling and future trends in clustering.
Defining Data Types
Understanding the different types of data is crucial for effectively analyzing and interpreting information. Data comes in various forms, each with unique characteristics and applications. This knowledge allows us to select appropriate tools and techniques for extracting insights and making informed decisions.
Data Type Overview
Data types are fundamental classifications that describe the nature and structure of information. Different data types have distinct properties, which influence how they are stored, processed, and analyzed. Knowing these characteristics is essential for building effective data models and algorithms.
Categorization of Data Types
This section presents a structured overview of 10 distinct data types, their characteristics, and potential applications.
| Type | Description | Use Case |
|---|---|---|
| Numerical Data | Represents quantities or measurements. Can be discrete (integers) or continuous (decimals). | Scientific research, financial analysis, statistical modeling, and engineering applications. Examples include temperature readings, stock prices, and population counts. |
| Categorical Data | Represents categories or groups. Can be nominal (unordered, like colors) or ordinal (ordered, like education levels). | Market research, customer segmentation, demographic studies, and quality control. Examples include customer preferences, product ratings, and survey responses. |
| Text Data | Represents textual information, including words, sentences, and paragraphs. | Natural language processing (NLP), sentiment analysis, document classification, and information retrieval. Examples include customer reviews, news articles, and social media posts. |
| Date and Time Data | Represents points or intervals in time. | Tracking events, scheduling appointments, analyzing trends over time, and creating timelines. Examples include birthdays, transaction dates, and project deadlines. |
| Boolean Data | Represents logical values, typically true or false. | Decision-making processes, filtering data, and creating conditional statements. Examples include yes/no answers, on/off switches, and success/failure indicators. |
| Image Data | Represents visual information in the form of pixels. | Image recognition, object detection, medical imaging, and facial recognition. Examples include photographs, medical scans, and satellite imagery. |
| Audio Data | Represents sound waves. | Speech recognition, music analysis, sound classification, and audio processing. Examples include voice recordings, music files, and environmental sounds. |
| Video Data | Represents moving images. | Video analysis, surveillance, motion detection, and video editing. Examples include security footage, movies, and online tutorials. |
| Geographic Data | Represents locations on Earth. | Mapping, navigation, spatial analysis, and urban planning. Examples include addresses, coordinates, and satellite imagery. |
| Mixed Data | Combines multiple data types within a single dataset. | Comprehensive analysis of complex phenomena, merging different aspects of information. Examples include customer profiles that include demographic data, purchase history, and survey responses. |
Data Quality Considerations
High-quality data is the cornerstone of effective clustering. Without meticulous attention to data accuracy, completeness, and consistency, clustering algorithms can produce unreliable results. This section delves into the critical role of data quality, highlighting potential issues, and outlining strategies for enhancement to ensure robust and accurate clusters.
Importance of Data Quality for Clustering
Data quality directly impacts the accuracy and reliability of clusters. Inaccurate or incomplete data can lead to misclassifications, irrelevant groupings, and ultimately, diminished performance of marketing campaigns. Clean, well-structured data provides a solid foundation for algorithms to identify meaningful relationships and patterns, leading to more effective strategies. Precisely defined s contribute to accurate cluster formation, facilitating targeted advertising and optimized content creation.
Potential Issues Arising from Poor Data Quality
Several issues can arise from poor data quality, significantly impacting the effectiveness of clustering. Inconsistent data formats, missing values, and inaccurate data entries can all lead to misinterpretations. Inconsistent capitalization or spelling errors can lead to the misclassification of semantically related s. Outliers and irrelevant data points can skew the clustering process, resulting in less relevant and less effective clusters.
Inaccurate or incomplete data can also result in skewed cluster sizes and proportions, which can negatively impact the effectiveness of clustering strategies.
Strategies to Address and Improve Data Quality
Implementing rigorous data quality checks is essential for successful clustering. Data validation rules should be implemented to ensure accuracy and consistency across all data. Data cleansing procedures should identify and correct inconsistencies, including typos, formatting errors, and missing values. Data standardization is also important to ensure that s are represented consistently throughout the dataset, for example, all s should be in lowercase or uppercase.
Regular audits and reviews of the data are necessary to identify and address any emerging issues, thereby maintaining data quality over time.
Data Quality Impact on Clustering Accuracy
The quality of data directly affects the accuracy of the clustering process. Poor data quality leads to inaccurate clusters, which may not accurately reflect the relationships between s. This can hinder the effectiveness of marketing strategies. Conversely, high-quality data enables accurate cluster identification, leading to more effective marketing campaigns and improved ROI.
| Issue | Impact | Mitigation Strategy |
|---|---|---|
| Inconsistent Data Formats | Misinterpretation of relationships, inaccurate cluster formation. | Standardize data formats; ensure consistent capitalization, use of special characters, etc. |
| Missing Values | Incomplete cluster representations, skewed results, difficulty in identifying patterns. | Impute missing values using appropriate methods (e.g., mean imputation, regression). |
| Inaccurate Data Entries | Misclassifications, irrelevant groupings, inaccurate representations. | Validate data entries against predefined rules; use data cleaning tools and techniques. |
| Outliers | Skewed cluster characteristics, misleading results, reduced accuracy. | Identify and remove outliers; implement appropriate filtering mechanisms. |
Clustering Methods and Techniques
Unveiling the secrets of data organization, clustering methods provide a powerful toolkit for grouping similar data points. By identifying patterns and structures within datasets, these methods unlock valuable insights, enabling us to categorize, segment, and understand the inherent relationships between different data elements. This process, fundamental to various data analysis applications, can reveal hidden trends, predict future behavior, and enhance decision-making processes.Clustering algorithms are categorized based on the underlying principles they employ, each with its own strengths and weaknesses.
Understanding these differences is crucial for selecting the most appropriate technique for a given dataset and analysis objective. The effectiveness of a clustering method depends heavily on the nature of the data and the desired outcome. Choosing the right algorithm ensures accurate and meaningful results.
Different Clustering Methods
Various algorithms exist for grouping similar data points, each with its own strengths and weaknesses. These methods vary in their computational complexity, scalability, and suitability for different types of data. Choosing the right method depends on the specific characteristics of the dataset and the desired outcome.
- K-means Clustering: This widely used algorithm aims to partition data into k clusters, where each data point belongs to the cluster with the nearest mean (centroid). It’s computationally efficient and relatively straightforward to implement, making it suitable for large datasets. A key consideration is determining the optimal number of clusters (k). Examples include customer segmentation, document categorization, and image compression.
- Hierarchical Clustering: This method creates a hierarchy of clusters by successively merging or splitting clusters based on similarity measures. It offers a visual representation of the relationships between clusters, providing a comprehensive understanding of the data’s structure. However, it can be computationally intensive for large datasets and is less suitable for cases requiring a specific number of clusters.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): This algorithm groups data points based on their density. It effectively identifies clusters of varying shapes and sizes, including outliers (noise points). It’s particularly useful for datasets with complex cluster structures and noisy data. For instance, anomaly detection, customer churn prediction, and spatial data analysis.
- Gaussian Mixture Models (GMM): This method assumes that data points are generated from a mixture of Gaussian distributions. It’s suitable for data exhibiting a Gaussian-like structure. It can handle overlapping clusters effectively, offering a flexible approach to clustering. Examples include image segmentation, medical diagnosis, and social network analysis.
Comparison of Clustering Methods
A comprehensive understanding of different clustering methods is essential for selecting the appropriate technique for a specific task. The following table summarizes the key characteristics of various algorithms.
| Method | Description | Strengths | Weaknesses |
|---|---|---|---|
| K-means | Partitions data into k clusters based on the distance to centroids. | Simple, efficient, scalable to large datasets. | Requires specifying k, sensitive to outliers, assumes spherical clusters. |
| Hierarchical | Creates a hierarchy of clusters by merging or splitting based on similarity. | Visual representation of cluster relationships, handles various cluster shapes. | Computationally intensive, less suitable for large datasets, no predefined number of clusters. |
| DBSCAN | Groups data points based on density, identifies clusters and outliers. | Handles clusters of arbitrary shapes, robust to outliers. | Parameter tuning can be challenging, sensitive to density variations. |
| GMM | Assumes data from a mixture of Gaussian distributions. | Handles overlapping clusters, flexible to various data distributions. | Computationally intensive, assumes data follows Gaussian distribution. |
Data Representation and Transformation
Data representation and transformation are crucial steps in the clustering process. Effective clustering hinges on the way data is presented to the algorithm. Transforming data into a suitable format allows the algorithm to identify patterns and relationships more efficiently, leading to better cluster quality. This often involves preparing data for clustering by handling missing values, outliers, and inconsistencies, normalizing the data to a common scale, and selecting relevant features.The goal of these transformations is to enhance the clustering algorithm’s ability to identify meaningful patterns in the data.
This results in more accurate and insightful clusters. Data transformations can include feature scaling, normalization, and selection, all aimed at creating a more suitable representation for the clustering algorithm. The improved data representation allows the algorithm to identify meaningful patterns more accurately and leads to more robust and reliable clusters.
Feature Engineering and Selection
Feature engineering and selection are vital for improving clustering results. Creating new features from existing ones (feature engineering) can capture complex relationships within the data, while removing irrelevant features (feature selection) reduces noise and improves efficiency. Feature engineering often involves combining or transforming existing attributes to create more informative ones. Feature selection methods aim to identify the most important features, discarding less significant ones.Feature engineering and selection strategies can be highly effective in enhancing the quality of clustering.
Techniques like polynomial features, interaction features, and normalization techniques can enhance the representation of the data. Feature selection methods, like filter methods, wrapper methods, and embedded methods, can identify relevant features.
Data Normalization and Standardization
Data normalization and standardization are essential for ensuring that different features contribute equally to the clustering process. Normalization scales the data to a specific range, while standardization transforms the data to have a mean of zero and a standard deviation of one. This ensures that features with larger values do not dominate the clustering process.These techniques can significantly improve clustering results.
Normalization methods like min-max scaling, z-score normalization, and others can improve clustering performance. Standardization, also known as z-score normalization, is particularly useful when features have different units or scales. By standardizing features, we ensure they have similar ranges and weights.
Data Preprocessing Flowchart for Clustering
This flowchart illustrates the typical steps in data preprocessing for clustering. It starts with data collection, followed by data cleaning, which includes handling missing values and outliers. Then, features are engineered and selected. Finally, data normalization and standardization are applied to improve clustering results.
Evaluating Clustering Performance: 10 Types Of Data For Your Keyword Clustering Wish List
Assessing the quality of a clustering solution is crucial for determining the effectiveness of the chosen approach. A poorly performing clustering algorithm can lead to misinterpretations and inaccurate analyses. This section delves into various metrics for evaluating clustering quality, illustrating their use and significance.Evaluating clustering performance goes beyond simply observing the clusters; it involves quantifying their quality using metrics tailored to the specific task.
These metrics provide a numerical representation of how well the clustering algorithm has grouped data points, allowing for objective comparisons across different clustering approaches and datasets.
Clustering Evaluation Metrics
Understanding the performance of a clustering algorithm is paramount for ensuring meaningful insights. Different metrics cater to various aspects of cluster quality, such as compactness within clusters and separation between clusters. Below are some commonly used metrics:
- Silhouette Coefficient: This metric measures how similar a data point is to its own cluster compared to other clusters. A higher Silhouette Coefficient indicates better-defined clusters. A value of 1 signifies that a data point is far from other clusters and close to its own, whereas a value of -1 suggests the opposite.
- Davies-Bouldin Index: This index quantifies the average similarity between clusters. A lower Davies-Bouldin Index suggests better-separated clusters. A value of 0 indicates perfectly separated clusters, while higher values signify overlapping clusters.
- Calinski-Harabasz Index: This metricevaluates the ratio of the between-cluster variance to the within-cluster variance. A higher Calinski-Harabasz Index indicates better-separated and more compact clusters. It measures how well the clusters are separated from each other and how compact they are internally.
Significance of Cluster Validity Indices
Cluster validity indices provide a crucial framework for assessing the quality of a clustering solution. They go beyond subjective interpretations and offer objective measures for comparing different clustering outcomes. Their use is essential for validating the clusters obtained from an algorithm and selecting the best-performing approach for the given dataset.
- Identifying Optimal Number of Clusters: Validity indices help in determining the optimal number of clusters. Analyzing the indices across various cluster numbers allows for a more informed decision about the appropriate number of clusters to represent the data effectively.
- Comparing Clustering Algorithms: Comparing different clustering algorithms on the same dataset using validity indices provides a robust means of evaluating their performance and selecting the algorithm that best suits the data.
- Assessing Clustering Robustness: Cluster validity indices help evaluate the robustness of the clustering solution. If the index is sensitive to the specific data points, the clustering solution might not be robust.
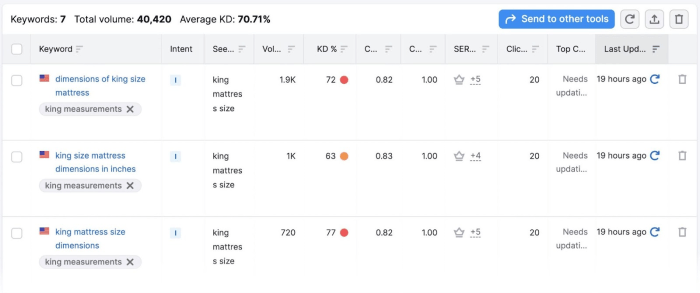
Calculating Metrics on a Sample Dataset
To illustrate the calculation process, consider a simple dataset of customer ages, with the following data points: 25, 30, 35, 40, 45, 28, 32, 38, 43,
50. Assume we have clustered this data into two clusters (Cluster 1
25, 28, 30, 32; Cluster 2: 35, 38, 40, 43, 45, 50). A calculation for the Silhouette Coefficient is beyond the scope of this section but examples can be found online.
| Metric | Formula | Interpretation |
|---|---|---|
| Silhouette Coefficient |
|
Measures how similar a data point is to its own cluster compared to other clusters. A higher value indicates better-defined clusters. |
| Davies-Bouldin Index |
|
Quantifies the average similarity between clusters. A lower value suggests better-separated clusters. |
| Calinski-Harabasz Index |
|
Evaluates the ratio of between-cluster variance to within-cluster variance, with higher values indicating better separation and compactness. |
Real-World Application Examples
Data clustering isn’t just a theoretical concept; it’s a powerful tool with real-world applications across diverse industries. By grouping similar data points, businesses can gain valuable insights and make data-driven decisions. This section will explore three practical examples, highlighting the specific data types used, how clustering results aided problem-solving, and the overall impact on the respective industries.
Customer Segmentation in E-commerce
Understanding customer behavior is crucial for e-commerce success. Clustering techniques can segment customers based on purchasing patterns, browsing history, demographics, and other relevant factors.
- Data Types: Transaction data (purchase history, product categories), customer demographics (age, location, interests), website browsing behavior (page views, time spent on site), and survey responses.
- Clustering Results: Clustering algorithms identify distinct customer segments, each with unique characteristics and needs. For example, a segment might consist of high-value customers who frequently purchase premium products, while another segment might be composed of budget-conscious shoppers.
- Problem Solved: Tailoring marketing campaigns and product recommendations to specific customer segments increases conversion rates and customer lifetime value. Targeted promotions and personalized offers lead to higher customer satisfaction and revenue generation.
“By understanding the specific needs and preferences of different customer segments, e-commerce businesses can optimize their marketing strategies and product offerings, leading to a more profitable and sustainable business model.”
Disease Diagnosis and Prediction in Healthcare
Clustering can assist in identifying patterns in patient data, potentially leading to earlier disease diagnosis and improved treatment outcomes.
- Data Types: Medical records (symptoms, lab results, diagnoses), patient demographics, lifestyle factors, and genetic information.
- Clustering Results: Clustering algorithms can group patients with similar medical conditions or risk factors. This allows healthcare providers to identify potential disease outbreaks, develop targeted interventions, and predict the likelihood of certain diseases based on specific patient characteristics.
- Problem Solved: Clustering can support early disease detection and personalized treatment plans. By identifying clusters of patients with similar characteristics, researchers can gain insights into disease patterns and potential risk factors, leading to better prevention strategies.
“Clustering medical data can significantly improve disease diagnosis and treatment. Identifying patterns and subgroups within patient populations can aid in developing targeted interventions and predicting the likelihood of specific health outcomes.”
Fraud Detection in Financial Institutions
Clustering algorithms are used to identify unusual transaction patterns and flag potentially fraudulent activities.
Thinking about 10 types of data for your keyword clustering wish list? Crucially, you’ll want to consider how to ensure your website’s pages are properly optimized, especially when it comes to search engine crawlers. This often involves using a canonical tag or redirect canonical tag or redirect to prevent duplicate content issues. Knowing which keywords are most important for your different pages is key for successful keyword clustering, so gathering the right data is vital for this process.
It’s a good idea to start thinking about the types of data you’ll need to build your keyword clustering wish list now.
- Data Types: Transaction data (amount, time, location, merchant type), customer demographics, account activity, and network information.
- Clustering Results: Clustering techniques can group transactions into clusters based on similarity. Transactions that deviate significantly from the typical patterns within a cluster are flagged as potential fraud.
- Problem Solved: Early detection of fraudulent activities helps financial institutions minimize financial losses and maintain customer trust. By identifying and preventing fraudulent transactions, financial institutions can protect their assets and maintain the integrity of their systems.
“Clustering techniques help financial institutions identify and prevent fraudulent activities by detecting unusual transaction patterns. This proactive approach protects both the institution and its customers from financial harm.”
Visualizing Clustering Results
Unveiling the hidden structures within your data is crucial for understanding and leveraging the insights derived from clustering analysis. Visualizations play a vital role in interpreting the results, allowing for quick identification of cluster patterns, outliers, and overall cluster distribution. This section delves into various visualization methods, their strengths and weaknesses, and how to effectively represent clusters in 2D and 3D spaces.
So, you’re dreaming up 10 types of data for your keyword clustering wish list? Knowing how crucial social media is for small businesses, like understanding why is social media marketing important for small business , is key. This insight will inform your data choices, helping you refine your keyword clusters for maximum impact and efficiency. Think about what data points will best help you reach your ideal customers, and you’ll be on the right track.
Methods for Visualizing Clustering Results
Effective visualization is essential for interpreting the outcome of clustering analysis. Different methods cater to various data characteristics and desired insights. Choosing the right method depends on the dimensionality of the data and the specific information you want to extract.
2D Scatter Plots
Scatter plots are a fundamental visualization technique for displaying clusters in two-dimensional space. Each data point is represented as a point on a graph, with the x and y axes representing two features. Points belonging to the same cluster are typically colored similarly.
Advantages: Simple to create and interpret, offering a clear visual representation of cluster separation. Useful for identifying clusters with distinct boundaries and outliers.
Disadvantages: Limited to visualizing data with only two features. Overlapping clusters might be challenging to distinguish. The choice of features for the axes can significantly influence the visualization.
Example: Consider a dataset of customer purchases categorized by product type. A scatter plot could visualize customer spending on clothing (x-axis) and electronics (y-axis), with different colors representing distinct customer segments (clusters).
3D Scatter Plots
Extending the concept of scatter plots to three dimensions, 3D scatter plots offer a more comprehensive visualization for datasets with three relevant features. Each point’s position is determined by its values along three axes.
Advantages: Provides a richer understanding of cluster structures by visualizing data in three dimensions, potentially revealing more intricate relationships. Helps in identifying complex patterns and structures that might not be evident in 2D visualizations.
Disadvantages: Can be challenging to interpret, as depth perception can be a factor. Requires more computational resources for rendering and may not be suitable for datasets with a large number of data points.
Example: A medical dataset could utilize a 3D scatter plot to visualize patients’ blood pressure (x-axis), cholesterol levels (y-axis), and age (z-axis), with different colors representing various patient categories.
Hierarchical Clustering Dendrograms
Dendrograms provide a hierarchical representation of clusters, showing the relationships between data points and the merging process during the clustering procedure.
So, you’re dreaming up 10 types of data for your keyword clustering wish list? Knowing your target audience inside and out is key, and a solid grasp of content marketing strategies can really help. Taking a content marketing training course might be just the boost you need to refine your keyword research and build a more effective content strategy.
After all, the more data you have, the better your keyword clusters will be, and that’s the ultimate goal.
Advantages: Useful for visualizing the hierarchical structure of clusters. Allows for identifying the proximity of clusters and the level of similarity between data points.
Disadvantages: Can be complex to interpret, especially with large datasets. Might not be suitable for visualizing clusters with non-hierarchical structures.
Data Handling and Management
Efficient data handling and management are crucial for successful clustering projects. Poorly managed data can lead to inaccurate results and wasted resources. Robust storage, retrieval, and governance systems are essential to ensure the quality and security of the data used for analysis. Proper data handling also helps maintain consistency and reliability throughout the project lifecycle.
Data Storage and Retrieval
Effective data storage and retrieval are paramount for efficient clustering analysis. The choice of storage method depends heavily on the volume, velocity, and variety of data, as well as the required query speed. Relational databases (SQL) are well-suited for structured data, while NoSQL databases are better for unstructured or semi-structured data. Cloud-based storage solutions offer scalability and accessibility advantages, while distributed file systems provide high throughput for large datasets.
Data Governance for Clustering
Data governance is critical for ensuring the quality, consistency, and trustworthiness of data used in clustering. It establishes clear policies and procedures for data management, including data quality rules, access controls, and data lineage tracking. A robust data governance framework helps maintain data accuracy, minimizes errors, and ensures compliance with regulations.
Data Security and Privacy Considerations, 10 types of data for your keyword clustering wish list
Data security and privacy are paramount in clustering projects, especially when dealing with sensitive information. Protecting data from unauthorized access, modification, or disclosure is crucial. Implementing appropriate security measures, including access controls, encryption, and data masking techniques, is essential. Adhering to privacy regulations, like GDPR, is vital for maintaining ethical and legal compliance.
- Data Encryption: Encrypting sensitive data both in transit and at rest is crucial. Strong encryption algorithms, like AES-256, should be used to protect data confidentiality. Regular audits of encryption systems and key management practices are essential.
- Access Controls: Implement granular access controls to limit access to sensitive data only to authorized personnel. Role-based access control (RBAC) can be used to restrict data access based on user roles and responsibilities. Regularly review and update access permissions to ensure compliance with security policies.
- Data Masking: Data masking techniques can be used to protect sensitive data without removing it entirely from the dataset. These techniques can replace sensitive information with pseudonyms or substitute values while maintaining the statistical properties of the data. Masking is beneficial for research involving sensitive information, like financial records or medical data.
- Compliance with Regulations: Adhering to data privacy regulations, like GDPR (General Data Protection Regulation), is vital. These regulations dictate how personal data can be collected, used, and shared. Data governance policies must reflect these regulations and ensure compliance with them.
Future Trends and Developments
The field of data clustering is constantly evolving, driven by advancements in computing power, data volume, and algorithmic sophistication. This dynamic landscape necessitates a forward-thinking approach to understanding emerging trends and technologies, which will shape the future of data analysis and interpretation. The ability to effectively leverage these trends will be crucial for extracting meaningful insights and solving complex problems in various domains.
Emerging Trends in Data Clustering
The future of data clustering is marked by several key trends. These trends include the increasing use of sophisticated algorithms, the integration of data from diverse sources, and the application of machine learning techniques. The rise of big data necessitates scalable clustering methods capable of handling vast datasets efficiently. Additionally, the need for explainable AI in clustering algorithms is becoming increasingly important to build trust and foster better understanding of the insights derived.
Advanced Clustering Algorithms
The development of more sophisticated clustering algorithms is a key trend. These algorithms are designed to handle complex data structures, noisy data, and high-dimensional datasets. Algorithms like deep learning-based clustering methods are being explored, promising improved performance and the ability to discover hidden patterns in intricate data relationships. Hybrid approaches combining traditional clustering techniques with deep learning are also gaining traction, allowing for a more comprehensive understanding of data structures.
Integration of Diverse Data Sources
Data clustering is increasingly being applied to datasets from multiple sources, including social media, sensor networks, and scientific experiments. This trend highlights the importance of integrating data from diverse sources and formats. The development of unified data representation frameworks and efficient data integration techniques is essential for leveraging the power of heterogeneous data in clustering tasks. This multifaceted approach promises to uncover richer insights than those obtainable from single-source analysis.
Impact of Machine Learning
Machine learning is significantly impacting the future of data clustering. Techniques like deep learning and reinforcement learning are being integrated into clustering algorithms to improve accuracy, efficiency, and the ability to discover complex patterns. Furthermore, the integration of machine learning allows for automatic feature selection, parameter tuning, and adaptive clustering strategies, leading to more robust and accurate clustering outcomes.
This trend underscores the increasing interconnectedness of machine learning and data clustering.
Scalability and Efficiency
The ability to handle massive datasets is crucial for data clustering in various applications. Efficient algorithms and parallel processing techniques are essential for addressing the growing volume of data. Cloud computing and distributed computing frameworks are providing solutions to manage the computational requirements of large-scale clustering problems. The development of specialized hardware, such as GPUs and FPGAs, is further enhancing the scalability and efficiency of clustering tasks.
Explainable AI in Clustering
The need for explainable AI in data clustering is growing rapidly. This is driven by the desire to understand the rationale behind the clustering results and to build trust in the insights derived. Techniques for visualizing and interpreting clustering models are crucial to this trend. Furthermore, methods that provide explanations and justifications for the clustering decisions are emerging, which aims to address the need for transparency and accountability in data analysis.
Visualization and Interpretation
Visualizing clustering results is vital for understanding and interpreting the findings. Interactive dashboards and data visualization tools are enhancing the ability to explore clusters and their characteristics. This trend highlights the importance of clear and concise visualizations to communicate complex clustering results effectively to stakeholders. These tools provide valuable insights into the data’s structure and relationships, supporting better decision-making.
Data Handling and Management
Efficient data handling and management are crucial for successful data clustering. This involves developing robust data storage and retrieval systems, as well as methods for data preprocessing and cleaning. Furthermore, tools for managing large datasets and integrating diverse data sources are becoming essential for effective clustering. The ability to manage and maintain data quality is vital to ensure accurate and reliable clustering results.
Closure
In conclusion, mastering clustering requires a deep understanding of diverse data types and their applications. By carefully considering the 10 types Artikeld here, you can optimize your strategy, gaining valuable insights for your content and ultimately improving your performance. The detailed exploration of each data type, its characteristics, use cases, and integration within your clustering process provides a comprehensive approach to unlocking the power of clustering.