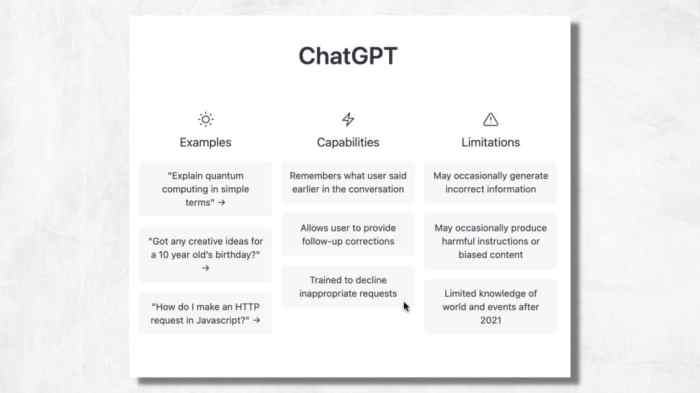
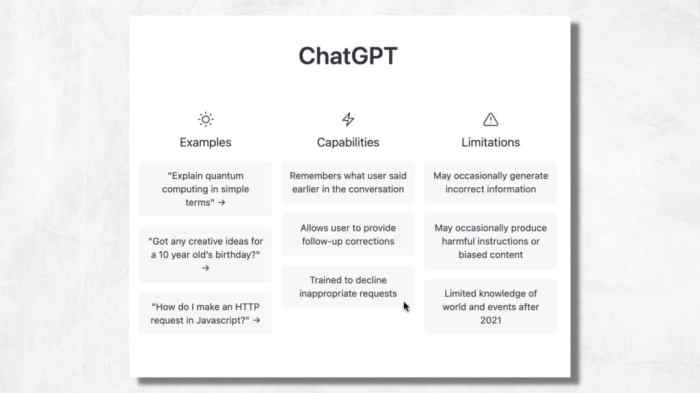
Chatgpt capabilities and limitations – Kami capabilities and limitations: This exploration delves into the fascinating world of large language models, examining their strengths and weaknesses in generating text, retrieving information, and understanding context. From the intricate architecture powering these models to the potential biases lurking within their training data, we’ll uncover the full spectrum of their abilities and limitations.
We’ll dissect the inner workings of these powerful systems, analyzing their capacity for creative text generation, information retrieval, and summarization. Furthermore, we’ll explore the practical applications of these models in diverse fields, alongside the potential risks and ethical considerations associated with their deployment.
Large Language Model Capabilities
Large language models (LLMs) are sophisticated AI systems capable of understanding, generating, and manipulating human language. Their ability to perform various natural language tasks has revolutionized fields like chatbots, translation, and content creation. This exploration delves into the inner workings of these models, highlighting their architecture, learning processes, and diverse applications.
Underlying Architecture of LLMs
LLMs are fundamentally neural networks, typically employing a transformer architecture. This architecture, unlike recurrent neural networks, allows the model to process entire sequences of text simultaneously, enabling more efficient and accurate understanding of context. Key to this architecture is the attention mechanism, which allows the model to weigh the importance of different words in a sentence relative to others.
This allows for a more nuanced understanding of relationships between words, essential for tasks like translation and summarization.
Components and Their Roles
The core components of an LLM are intricate and often interconnected. The input text is processed through an embedding layer, which converts words into numerical vectors. These vectors capture semantic meaning, enabling the model to understand relationships between words. Subsequently, the transformer layers use attention mechanisms to process the embedded words, considering their context within the entire input sequence.
The output layer then generates a probability distribution over possible next words, forming the basis for text generation. This process is iterative, enabling the model to generate coherent and contextually relevant text.
Learning from Vast Amounts of Data
LLMs learn from massive datasets of text and code. These datasets, often comprising millions or even billions of words, provide the model with examples of various language patterns, structures, and contexts. The model uses a process called backpropagation to adjust its internal parameters, minimizing the difference between its predictions and the actual text in the dataset. This iterative refinement allows the model to progressively improve its understanding and generation capabilities.
For example, training a model on a vast corpus of legal documents would allow it to understand legal language and potentially generate legal briefs or summaries.
Types of Tasks Performed, Chatgpt capabilities and limitations
LLMs excel at a wide array of natural language tasks. They can perform text summarization, translation, question answering, and dialogue generation. They are also adept at tasks involving sentiment analysis, where they can determine the emotional tone of a piece of text. The specific capabilities of a model are determined by the data it is trained on.
Comparison of Architectures
| Feature | Transformer-based | Recurrent Neural Networks (RNNs) ||—|—|—|| Processing method | Processes entire sequence simultaneously | Processes sequence sequentially, one word at a time || Contextual understanding | Excellent, due to parallel processing | Limited, struggles with long-range dependencies || Efficiency | More efficient for long sequences | Less efficient for long sequences || Parallelism | Highly parallelizable | Limited parallelism || Training time | Can be significantly longer | Typically faster to train || Performance | Generally superior for many tasks | Can be effective for simpler tasks |
ChatGPT’s impressive abilities are undeniable, but it’s not without its limitations. It excels at generating human-like text, but its understanding of context can sometimes falter. This reminds me of the crucial differences between a landing page and a homepage, which are both vital components of a website. A well-designed landing page is specifically focused on a single conversion goal, unlike a homepage which acts as a gateway to the whole site.
Understanding these nuanced differences can be helpful in crafting effective online strategies. Ultimately, while ChatGPT’s capabilities are vast, it’s essential to acknowledge its limitations and use it responsibly, just as carefully crafting a website’s structure and content is crucial for achieving desired results. landing page vs homepage
Text Generation Abilities
Large language models (LLMs) possess remarkable capabilities in generating human-quality text, spanning various styles and formats. Their ability to mimic human writing styles and produce coherent, contextually relevant content is a testament to their sophisticated architecture. This power allows for a wide range of creative applications, from crafting engaging narratives to generating technical documentation.These models learn intricate patterns and relationships from vast datasets of text, enabling them to produce outputs that closely resemble human-written content.
This proficiency stems from their deep understanding of grammar, syntax, and semantic structures within the language. However, it’s crucial to remember that while LLMs can generate impressively realistic text, their understanding of the world and nuances of human experience is still limited.
Strengths in Generating Human-Quality Text
LLMs excel at mimicking various writing styles. They can adapt to different tones, from formal academic prose to informal conversational language. Their training on extensive text corpora allows them to capture subtle stylistic cues, like word choice and sentence structure, contributing to the overall quality and realism of the generated text. This capability makes them valuable tools for writers and content creators.
Examples of Creative Text Outputs
LLMs can produce diverse creative text formats. They can generate poems with evocative imagery and rhythm, short stories with engaging plots, and scripts with believable dialogue. Furthermore, LLMs can compose musical pieces with specific moods and styles, showcasing their ability to create in various artistic mediums.For instance, a prompt requesting a sonnet about the beauty of a sunrise can result in a poem with a clear rhyme scheme and meter.
Similarly, a prompt for a short story about a journey across a fictional land can yield a narrative with vivid descriptions and compelling characters.
Factors Influencing Quality and Coherence
Several factors play a crucial role in determining the quality and coherence of generated text. The quality of the input prompt significantly impacts the output. A well-defined prompt with clear instructions and desired characteristics will yield more coherent and relevant results. The model’s training data also influences the output. If the training data lacks diverse perspectives or certain stylistic nuances, the generated text may reflect these limitations.
The model’s architecture and parameters further affect the generated text’s complexity and detail.
Table of Creative Text Formats
| Format | Description |
|---|---|
| Poems | Verse-based expressions of emotion, ideas, or experiences. |
| Short Stories | Narratives with characters, plots, and settings. |
| Scripts | Dialogue-driven narratives, often for plays or films. |
| Musical Pieces | Sequences of notes and rhythms, often with a specific mood or style. |
| Articles | Informative pieces on various topics. |
| Essays | pieces on a specific theme or idea. |
Methods for Evaluating Generated Text
Evaluating the quality of generated text involves a multifaceted approach. Human evaluation, using expert judges or crowdsourced feedback, remains a crucial method. This allows for a nuanced assessment of factors like style, coherence, and creativity. Quantitative metrics, such as fluency and grammatical correctness, can also provide objective measures of the generated text’s quality. Furthermore, comparing the generated text to human-written samples within the same genre can provide a comparative analysis.
These various methods contribute to a comprehensive evaluation of the generated text.
Information Retrieval and Summarization: Chatgpt Capabilities And Limitations
Large language models (LLMs) are increasingly capable of extracting and summarizing information from diverse sources. Their ability to understand context and relationships within text allows them to go beyond simple matching, enabling more nuanced and comprehensive information retrieval. This capability is crucial for tasks like research, news aggregation, and knowledge distillation.LLMs excel at understanding the context of a document and identifying key information, enabling efficient summarization of complex texts.
However, limitations remain in handling intricate or multifaceted information, requiring further development in areas like discerning fact from opinion and recognizing subtle nuances in meaning.
ChatGPT’s impressive language abilities are undeniable, but it’s crucial to understand its limitations. While it excels at generating human-like text, it lacks the real-world context and critical thinking skills of a human. Optimizing your blog posts for search engines, like by using proper formatting techniques in blog post formatting for search success , is important, but ultimately, a human touch adds nuance and critical analysis.
This means ChatGPT can be a great tool for drafting and generating content, but humans are still essential for the final review and strategic direction.
Information Extraction Capabilities
LLMs can extract information from a wide array of sources, including websites, documents, and databases. This extraction extends beyond simple matching to include understanding relationships and contextual nuances within the text. For instance, an LLM can identify the author, date, and key arguments of an article, even if those elements aren’t explicitly stated. The ability to extract structured information from unstructured text is a powerful tool for knowledge management and data analysis.
Effective Summarization Techniques
Various summarization techniques are employed by LLMs. One common approach involves identifying key sentences and phrases within a text and combining them into a concise summary. Another method focuses on extracting the most important information from different parts of the document and condensing it into a cohesive summary. For example, an LLM could summarize a scientific article by extracting the key findings, methodology, and conclusions, providing a concise overview for readers.
These techniques, when combined, can generate high-quality summaries from a range of document types.
Handling Complex or Nuanced Information
LLMs still face limitations in handling complex or nuanced information. Distinguishing between fact and opinion, recognizing subtle nuances in meaning, and understanding the context of ambiguous statements can be challenging. For instance, summarizing a philosophical debate or a legal case requiring intricate interpretations may present difficulties. The inherent ambiguity in human language and the need for sophisticated reasoning skills present hurdles to complete accuracy in these scenarios.
Comparison of Information Retrieval Approaches
Different approaches to information retrieval and summarization vary in their complexity and effectiveness. Traditional methods often rely on matching and statistical analysis, whereas LLMs utilize deep learning and contextual understanding. The latter approach generally produces more comprehensive and nuanced results, but the computational resources required can be substantial. This difference in approach reflects the ongoing evolution of information retrieval techniques.
Data Sources for Information Processing
| Data Source | Processing Capabilities |
|---|---|
| Web Pages | LLMs can extract information from web pages, including text, images, and metadata. |
| Documents (PDF, DOCX, TXT) | LLMs can process various document formats, extracting relevant data and generating summaries. |
| Databases | LLMs can query and extract data from databases, enabling analysis and summarization. |
| Social Media Posts | LLMs can process social media posts, extracting information, sentiment, and identifying trends. |
| News Articles | LLMs can efficiently summarize news articles, extracting key events and perspectives. |
Limitations and Biases

Large language models, while powerful, are not without their limitations. These models are trained on vast datasets of text and code, and these datasets often reflect existing societal biases. Consequently, the models can perpetuate and even amplify these biases in their generated text, leading to skewed or inappropriate outputs. Understanding these limitations is crucial for responsible use and development of these powerful tools.The biases embedded in training data can manifest in various ways, from subtle stereotypes to overt prejudices.
These biases are not deliberate; rather, they are unintended consequences of the data used to train the models. Recognizing these biases and mitigating their impact is essential for ensuring fairness and accuracy in the outputs of these models.
Potential Biases in Training Data
The training data for large language models is often a reflection of the world’s existing biases. This data can contain stereotypes, prejudices, and inaccuracies that are not necessarily intentional. For example, if a dataset predominantly features male protagonists in science fiction stories, the model might generate text that underrepresents female characters in similar contexts. This reflects the skewed representation in the training data.
Similarly, historical and societal biases related to gender, race, religion, and other factors can be ingrained in the models’ outputs. These biases are not simply errors but are a direct consequence of the data’s limitations.
Manifestations of Bias in Generated Text
The biases inherent in the training data can manifest in various ways in the generated text. These can range from subtle linguistic patterns to more overt expressions of prejudice. For example, a model trained on predominantly Western literature might generate text that reflects a Western worldview, potentially marginalizing or misrepresenting perspectives from other cultures.
Limitations in Understanding Context and Nuance
Large language models excel at mimicking human language but often struggle with subtleties of context and nuance. While they can generate grammatically correct and coherent text, they may not fully grasp the underlying meaning or implications of the information. For instance, a model might generate a response that is factually correct but insensitive or inappropriate due to a misunderstanding of the context.
ChatGPT, while impressive in its ability to generate human-like text, still has limitations. It can struggle with nuanced tasks and doesn’t possess real-world experience. This is where digital marketing strategies become crucial for small businesses. Learning the ten benefits of digital marketing for small businesses, like increased visibility and cost-effectiveness ( ten benefits of digital marketing for small businesses ), can help overcome some of these limitations.
Ultimately, combining ChatGPT’s strengths with a robust digital marketing plan offers a powerful toolkit for success.
This limitation highlights the need for careful evaluation of model outputs, particularly in sensitive or complex situations.

Examples of Model Struggles
Large language models sometimes struggle with providing accurate or appropriate responses in specific situations. For example, when asked to summarize complex historical events, the model might inadvertently present a biased interpretation if its training data lacks diverse perspectives. Likewise, generating creative content or nuanced discussions on sensitive topics requires a deeper understanding of the context that may be beyond the capabilities of current models.
These models might also generate factual errors, misinterpret complex questions, or provide responses that are illogical or nonsensical in the given context.
Comparison of Biases in Large Language Models
| Bias Type | Description | Example |
|---|---|---|
| Gender Bias | Overrepresentation or underrepresentation of certain genders in training data leading to skewed portrayals. | A model generating text that portrays women primarily in domestic roles, or underrepresenting female figures in STEM fields. |
| Racial Bias | Stereotyping or misrepresenting certain racial groups in training data, leading to prejudiced or inaccurate portrayals. | A model generating text that uses racial stereotypes or that perpetuates harmful racial narratives. |
| Cultural Bias | Overrepresentation of specific cultures or underrepresentation of others, potentially leading to cultural insensitivity or misrepresentation. | A model generating text that assumes a particular cultural norm or perspective, neglecting alternative interpretations or experiences. |
| Ideological Bias | Reflecting dominant ideologies in the training data, which may marginalize or misrepresent alternative perspectives. | A model generating text that promotes a particular political viewpoint or religious belief system while ignoring opposing viewpoints. |
Practical Applications
Large Language Models (LLMs) are rapidly transforming various sectors, offering unprecedented opportunities for automation, efficiency, and innovation. From streamlining customer interactions to revolutionizing educational approaches, these models are poised to reshape how we work, learn, and interact with information. Understanding the potential benefits and inherent risks is crucial for responsible deployment and ethical use.LLMs’ ability to process and generate human-like text makes them exceptionally versatile tools.
Their potential for practical application is vast, impacting industries from customer service to scientific research. However, it’s essential to approach these applications with caution, acknowledging the limitations and biases inherent in these models, and prioritizing ethical considerations.
Customer Service Applications
LLMs are proving to be highly effective in automating customer service interactions. They can handle routine inquiries, provide instant support, and even resolve simple issues without human intervention. This capability significantly reduces response times and frees up human agents to focus on more complex or sensitive cases. For example, chatbots powered by LLMs can answer frequently asked questions, schedule appointments, and provide basic troubleshooting guidance, leading to enhanced customer satisfaction and reduced operational costs.
This automation is particularly beneficial for businesses with high volumes of customer interactions.
Educational Applications
LLMs can revolutionize the educational landscape by providing personalized learning experiences. They can tailor learning materials to individual student needs, offer customized feedback on assignments, and even simulate real-world scenarios for practical application. This personalized approach can lead to improved comprehension and retention rates, potentially bridging educational gaps and fostering a more engaging learning environment. For instance, LLMs can create interactive exercises and simulations, providing students with immediate feedback and opportunities for self-assessment.
Research Applications
LLMs are becoming increasingly valuable research tools. They can process vast quantities of text data, identify patterns and trends, and generate summaries and insights. This capability can accelerate the pace of research in various fields, from medical research to social sciences. Researchers can leverage LLMs to analyze scientific literature, identify relevant research gaps, and generate hypotheses. For example, LLMs can summarize scientific articles, extract key findings, and suggest connections between different research areas.
Ethical Considerations
The deployment of LLMs in real-world settings raises important ethical considerations. Ensuring accuracy, fairness, and transparency in the output of these models is paramount. Care must be taken to avoid perpetuating biases present in the training data, and mechanisms for accountability and redress must be in place. Furthermore, the potential for misuse, such as the creation of misleading or harmful content, requires careful consideration and proactive measures.
Robust safeguards and ethical guidelines are crucial to mitigating these risks.
Importance of Human Oversight
While LLMs offer impressive capabilities, human oversight remains crucial for effective deployment. Humans must be involved in validating the output of these models, ensuring accuracy, and addressing potential biases or inaccuracies. Human judgment is indispensable for critical decision-making processes that involve LLM-generated information. This oversight also allows for adapting the models to specific contexts and refining their performance over time.
Table of Industries Benefiting from LLMs
| Industry | Potential Applications |
|---|---|
| Customer Service | Chatbots, automated responses, issue resolution |
| Education | Personalized learning, interactive exercises, automated feedback |
| Research | Data analysis, literature review, hypothesis generation |
| Healthcare | Diagnosis support, medication recommendations |
| Finance | Fraud detection, risk assessment |
| Legal | Document review, legal research |
| Journalism | Generating summaries, creating articles |
Future Directions
The field of large language models (LLMs) is rapidly evolving, promising both exciting advancements and complex challenges. As these models become more sophisticated, understanding their potential impact on society and identifying areas for improvement is crucial. This section delves into potential future developments, forecasting capabilities and limitations, and highlighting emerging research directions.
Potential Advancements in Capabilities
The next few years will likely see LLMs excelling in nuanced understanding and generation. Expect more sophisticated reasoning abilities, enabling LLMs to tackle complex problems and perform more abstract tasks. This includes better handling of ambiguity, context, and subtle nuances in language, leading to more human-like interactions and responses. Enhanced creativity and originality in text generation are also anticipated, potentially revolutionizing creative industries.
The ability to synthesize information from diverse sources, and to effectively distinguish between factual and fictional content will also see significant improvements.
Addressing Limitations and Biases
Current LLMs often exhibit biases present in the data they were trained on. Addressing these biases through improved training methodologies and data curation is critical. Future research will focus on developing techniques to identify and mitigate these biases, fostering fairer and more equitable models. Furthermore, ensuring robustness and preventing the propagation of misinformation will be a key area of focus.
Techniques to improve the accuracy and reliability of LLMs, especially in complex domains, will be developed.
Emerging Research Areas
Research into explainable AI (XAI) for LLMs is expected to accelerate. This will provide insights into how LLMs arrive at their conclusions, fostering trust and enabling better understanding of their decision-making processes. Furthermore, the development of more efficient and scalable training methods will be critical to address the computational demands of training increasingly complex models. Research will also concentrate on improving the robustness of LLMs, making them less susceptible to adversarial attacks and manipulation attempts.
Forecasted Advancements (Next 5-10 Years)
| Area | Potential Advancement | Example Impact |
|---|---|---|
| Contextual Understanding | LLMs will exhibit significantly improved understanding of complex contexts, encompassing nuances in language and societal implications. | More accurate summarization of lengthy documents, better comprehension of complex legal texts. |
| Bias Mitigation | Techniques for detecting and mitigating biases in training data will mature, leading to fairer and more equitable models. | Reduced gender or racial bias in generated text, more accurate representation of diverse populations. |
| Explainability | Methods for explaining the reasoning behind LLM outputs will be developed, enhancing trust and transparency. | Understanding why an LLM produced a particular response, enabling better debugging and troubleshooting. |
| Robustness | LLMs will be engineered to withstand adversarial attacks and manipulation attempts. | Protection against attempts to mislead the model, ensuring more reliable outputs in sensitive domains. |
| Efficiency | Training methods will be optimized for efficiency, enabling faster and cheaper model development. | Faster prototyping of new models and more frequent updates to existing models. |
Potential Impact on Society
The evolution of LLMs holds profound implications for society. In education, LLMs could personalize learning experiences and provide tailored support to students. In healthcare, LLMs can assist with diagnosis, drug discovery, and personalized treatment plans. However, ethical considerations, including data privacy, job displacement, and the potential misuse of LLMs, must be carefully addressed. The potential for societal disruption, whether positive or negative, is substantial and requires careful consideration.
Summary
In conclusion, large language models possess remarkable capabilities, but also significant limitations. While their potential for innovation is undeniable, careful consideration of their biases, limitations in nuanced understanding, and ethical implications is crucial for responsible development and deployment. The future of these models hinges on ongoing research and a proactive approach to mitigating potential harms while maximizing their benefits.