Common crawlability issues how to fix is a crucial aspect of website optimization. Understanding how search engine crawlers navigate your site is key to maximizing your search engine visibility and user experience. This post dives deep into identifying and resolving common problems, from robots.txt errors to server-side issues and content-related obstacles. We’ll cover everything from technical details to actionable steps for improving your site’s crawlability.
Knowing the common crawlability issues how to fix allows you to create a website that is easily accessible and understandable for search engine crawlers. This, in turn, boosts your search engine rankings, improving your website’s visibility and attracting more users.
Identifying Common Crawlability Problems: Common Crawlability Issues How To Fix
Website crawlability is crucial for search engine visibility and user experience. A website that’s not easily accessible to search engine bots results in lower rankings and potentially a poorer user experience. Understanding the common hurdles that prevent crawlers from properly indexing pages is vital for optimizing a website’s performance.Identifying and addressing these issues will lead to better search engine rankings, more organic traffic, and a more positive user experience.
Common Technical Crawlability Errors
Technical issues are often the root cause of crawlability problems. These errors can stem from server-side problems, or issues within the website’s code or structure. Addressing these problems directly improves the site’s accessibility for crawlers.
- Robots.txt Misconfiguration: Incorrectly configured robots.txt files can prevent crawlers from accessing crucial sections of the website. This can lead to missed pages and reduced indexing. For example, if a vital directory is blocked by the robots.txt file, crawlers cannot discover or index its content, thus affecting search engine visibility. Properly configuring this file to allow access to essential pages is critical.
- 404 Errors: Broken links, or pages returning a 404 error, signal to crawlers that the page no longer exists. This creates a bad user experience and negatively impacts the website’s reputation. Such errors might lead to lost users and a poor user experience, in addition to search engine penalties. Implementing a robust system to identify and resolve broken links is essential for both crawlability and user experience.
- Slow Loading Times: Sluggish loading times negatively affect user experience and potentially hurt crawlability. Slow-loading pages can cause crawlers to lose interest, leading to incomplete indexing. Optimizing page load times is a must for crawlability and user experience. This includes optimizing images, minimizing HTTP requests, and using a content delivery network (CDN) where appropriate.
Common Content-Related Crawlability Issues
Content-related issues can hinder a website’s ability to be crawled effectively. These problems often arise from poor content structure, or lack of sufficient metadata.
- Thin or Duplicate Content: Pages with minimal unique content or pages with identical content elsewhere on the website are not valuable to users and search engines. This can lead to lower rankings, because search engines prefer original and valuable content.
- Poorly Structured Pages: Poorly structured pages, with messy HTML, and a lack of semantic HTML elements, hinder crawlers’ ability to understand the content’s context and structure. This can lead to poor indexing.
- Missing or Poor Metadata: Missing or poorly optimized metadata (title tags, meta descriptions, alt text for images) does not provide sufficient information for crawlers to understand the content. This results in reduced visibility and poor search engine rankings.
Frequency and Severity of Crawlability Problems
The following table compares the frequency and severity of various crawlability problems.
| Error Type | Frequency | Severity | Impact on Visibility |
|---|---|---|---|
| Robots.txt Misconfiguration | High | High | Significant reduction in indexed pages |
| 404 Errors | Medium | Medium | Reduced visibility due to broken links and poor user experience |
| Slow Loading Times | High | Medium | Potential for incomplete indexing and negative user experience |
| Thin or Duplicate Content | Medium | Medium | Lower rankings due to lack of unique content |
| Poorly Structured Pages | Medium | Medium | Difficult for crawlers to understand content structure |
| Missing or Poor Metadata | High | Medium | Reduced visibility due to lack of clear page description |
Robots.txt Issues and Solutions
A crucial aspect of website crawlability is the robots.txt file. This file acts as a guide for search engine crawlers, instructing them on which parts of your site they are allowed to access. Properly configured, it helps prevent unwanted crawling and ensures that only relevant content is indexed. Conversely, a poorly configured robots.txt file can hinder your website’s visibility in search results.Understanding how robots.txt works and common errors is essential for optimizing your website’s discoverability.
This involves knowing how to configure it for optimal performance and avoiding mistakes that could hinder your site’s ranking.
Common Robots.txt Problems
Incorrect directives, missing files, or outdated rules within the robots.txt file can lead to significant crawlability issues. Search engine crawlers may either miss important content or crawl unwanted resources, which can negatively impact search engine rankings. These issues are often subtle but can have a noticeable impact on site visibility.
Checking for Accuracy and Completeness
Verifying the accuracy and completeness of your robots.txt file is vital for ensuring proper crawling behavior. Use a dedicated robots.txt validator tool. These tools are readily available online and will check for common errors, such as incorrect syntax, disallowed patterns, and missing directives. Inspecting the file manually is also important to ensure that the directives accurately reflect your intentions.
Thorough examination ensures proper crawlability.
Controlling Crawling with Robots.txt
The robots.txt file allows you to exert control over which parts of your website are accessible to search engine crawlers. This control is essential for managing crawling behavior, ensuring that valuable content is indexed while keeping irrelevant or sensitive information out of search results. This is a critical aspect of website optimization.
Robots.txt Directives
A robots.txt file uses specific directives to control crawling behavior. Understanding these directives is essential for creating an effective robots.txt file. The following table illustrates various directives and their effects:
| Directive | Description | Example |
|---|---|---|
| User-agent | Specifies the search engine bot (e.g., Googlebot, Bingbot) the directive applies to. | User-agent: Googlebot |
| Disallow | Specifies the URLs that the specified user-agent should not crawl. | Disallow: /admin/ |
| Allow | Specifies the URLs that the specified user-agent is allowed to crawl, overriding any disallow directives. | Allow: /products/* |
| Sitemap | Provides a link to a sitemap, which helps search engines discover and crawl your site’s content more efficiently. | Sitemap: https://www.example.com/sitemap.xml |
| Crawl-delay | Specifies the time in seconds that a bot should wait between requests. Useful for large sites to prevent overwhelming the server. | Crawl-delay: 1 |
HTTP Status Codes and their Significance
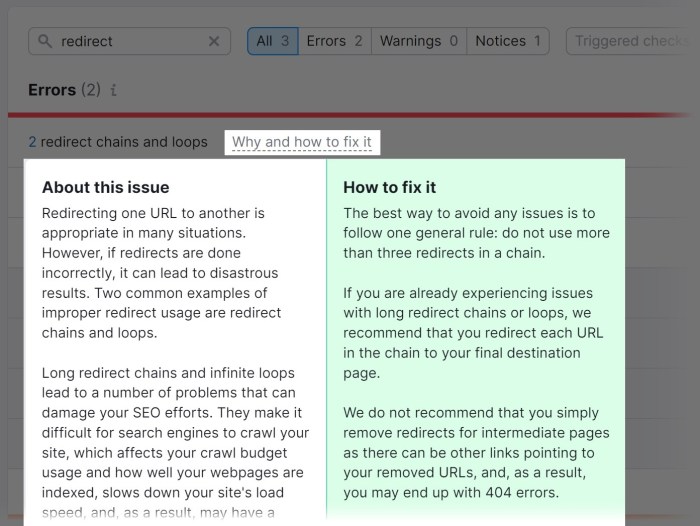
Understanding HTTP status codes is crucial for diagnosing crawlability issues. These codes, returned by a web server in response to a crawler’s request, provide valuable information about the server’s reaction to the request. A crawler encountering a series of errors will likely stop crawling the site, potentially missing important content.HTTP status codes, ranging from 1xx to 5xx, convey the outcome of a server’s interaction with a crawler’s request.
Fixing common crawlability issues is crucial for any website, especially when you’re trying to optimize your SEO. One often overlooked aspect, particularly for scaling startups, is the importance of efficiently structuring your website’s architecture. Think about how scaling startups with frugal innovation can translate to making your site easily navigable for bots. Ultimately, understanding and addressing these issues is vital for broader online visibility.
They’re not just numbers; they are key indicators of potential problems that impact a website’s visibility to search engines.
HTTP Status Codes Indicating Crawlability Problems
HTTP status codes are a critical part of website health and crawlability. Knowing which codes indicate issues and what they mean is essential for maintaining a website’s accessibility to search engines. Errors can range from temporary issues to more serious problems.
Meaning and Impact of Common Status Codes
A variety of HTTP status codes can indicate problems for web crawlers. Understanding their meaning and potential impact on crawling is crucial for troubleshooting. Each code signifies a different response from the server, revealing potential issues.
Examples of Interpreting HTTP Error Messages
Interpreting HTTP error messages is essential for troubleshooting crawlability problems. Analyzing the messages can pinpoint the source of the problem, whether it’s a temporary issue or a more significant problem.
Table of Common HTTP Status Codes
This table presents common HTTP status codes that can affect crawlability, their descriptions, and potential solutions. This information can assist in diagnosing and resolving crawlability issues quickly.
| Status Code | Description | Potential Fixes |
|---|---|---|
| 400 Bad Request | The server cannot understand the request due to invalid syntax or parameters. | Review the crawler’s request for errors in the format or parameters, fix any issues with the request, or check server-side configurations. |
| 403 Forbidden | The server understands the request but refuses to fulfill it. | Verify the crawler’s user-agent string and credentials, ensure the Robots.txt file is correctly configured, and possibly contact the website administrator. |
| 404 Not Found | The requested resource is not found on the server. | Check the URL for typos or outdated links, verify the file exists on the server, and ensure proper directory structure. |
| 408 Request Timeout | The server did not receive a request within a specific time frame. | Ensure the crawler’s connection is stable and the request is not taking too long to process, or check the server configuration for timeouts. |
| 500 Internal Server Error | A generic error indicating an unexpected issue on the server. | Review server logs for more specific error messages, check server resources (CPU, memory, disk space), and contact the website administrator. |
| 503 Service Unavailable | The server is currently unable to handle the request due to temporary overload or maintenance. | Check the website status for maintenance or overload, wait for the service to become available, and possibly contact the website administrator. |
Server-Side Issues Affecting Crawlability

Your website’s server is the backbone of your online presence. A malfunctioning server can severely impact search engine crawlers’ ability to access and index your content, hindering your website’s visibility in search results. Understanding server-side problems and how to fix them is crucial for maintaining a healthy online presence.Server-side issues often manifest as slow loading times, unresponsive pages, or outright errors.
These problems, though originating on the server, directly affect the user experience and, critically, the crawlability of your website. Search engine bots rely on consistent and timely responses from your server to effectively crawl and index your pages.
Slow Response Times
Slow server response times can significantly impact crawl performance. Crawlers, just like users, have time constraints. If your server takes an excessively long time to respond to a crawler’s request, it might give up before fully accessing all the content on a page, leading to incomplete indexing or even missing pages altogether. This translates to a reduced presence in search results.
For instance, if a crawler takes more than a few seconds to load a page, it might move on to other websites, potentially missing critical content.
Server Errors
Server errors, such as HTTP 500 errors (Internal Server Error) or 503 errors (Service Unavailable), prevent crawlers from accessing pages altogether. These errors indicate problems with your server’s functionality, potentially stemming from overloaded resources, configuration issues, or software malfunctions. These errors can make your site appear unreliable to search engines, which in turn can negatively impact its ranking and indexation.
Insufficient Server Resources
Insufficient server resources, like insufficient RAM or CPU capacity, can lead to slow response times and frequent server errors. When a server is overwhelmed with requests, it struggles to process them effectively. This can cause delays in loading pages for both users and crawlers, ultimately hindering crawl performance and impacting indexation.
Troubleshooting and Fixing Server-Side Issues
Addressing server-side issues requires a systematic approach. First, monitor server performance using tools like server logs and monitoring dashboards. These tools help identify patterns and pinpoint the root cause of slowdowns or errors. Once you’ve identified the problem, implement solutions. These may include upgrading server hardware, optimizing server configurations, or implementing caching mechanisms to reduce the load on the server.
Comparison of Server Configurations and Crawling Speed
| Configuration | Speed | Potential Crawlability Issues |
|---|---|---|
| Shared hosting with limited resources | Slow | Frequent server errors, slow response times, potential for website downtime |
| Dedicated server with optimized configuration | Fast | Minimal to no issues, consistent crawling |
| Cloud server with auto-scaling | Variable, often fast | Potential for occasional slowdowns during peak loads, but generally robust |
Sitemap Issues and Optimizations
Sitemaps are crucial navigational tools for search engine crawlers, acting as blueprints for your website’s structure. They guide crawlers through the labyrinth of your content, ensuring they can discover and index all important pages. A well-structured and maintained sitemap significantly enhances crawlability, leading to improved search engine rankings.Sitemap files are essentially an XML document listing all the important URLs on your website, making it easier for search engine crawlers to understand the site’s architecture.
This structured overview aids crawlers in prioritizing pages for indexing and ensures they don’t miss crucial content.
Sitemap Format and Structure, Common crawlability issues how to fix
Correctly formatted sitemaps are vital for crawlers to understand and process the information. Errors in the XML format, incorrect use of tags, or invalid data within the sitemap file can cause problems. Crawlers may ignore the sitemap entirely or misinterpret the information, resulting in incomplete indexing. For instance, a missing closing tag or a wrongly structured URL element can severely impact the crawlability of the site.
Common Sitemap Issues
Several issues can hinder the effectiveness of sitemaps. One common problem is an incorrect XML format. If the sitemap doesn’t adhere to the XML specification, crawlers might not be able to parse it, leading to indexing errors. Missing URLs, especially for important sections of your website, can also prevent crawlers from accessing crucial content. Outdated information, such as links to pages that have been removed or significantly modified, creates confusion for crawlers, potentially leading to incorrect indexing and a negative impact on .
Strategies for Effective Sitemap Generation and Maintenance
Generating and maintaining effective sitemaps requires a strategic approach. Use a sitemap generator tool to ensure the sitemap is correctly formatted according to the latest XML standards. Regularly update the sitemap to reflect changes in your website structure. Include all important pages, including new content, updated pages, and removed pages. The frequency of sitemap updates depends on the website’s activity; frequently updated sites need more frequent updates.
Sitemap Types and Effectiveness
Different types of sitemaps cater to specific needs. A comparison table below Artikels the benefits and drawbacks of various sitemap types:
| Sitemap Type | Benefits | Drawbacks |
|---|---|---|
| XML Sitemap | The most common type, understood by most search engines. Excellent for comprehensive site indexing. | Requires careful structure and format to avoid errors. Can be large for very complex sites. |
| Image Sitemap | Allows search engines to discover and index images on your website. Crucial for image-heavy sites. | Less crucial for sites with minimal images. Can be ignored by search engines if not correctly implemented. |
| Video Sitemap | Specifically targets videos on your site, ensuring they are discoverable by search engines. | Only relevant for video-centric sites. Not as crucial as other sitemaps for general crawlability. |
| News Sitemap | Designed for news websites, aiding in the discovery and indexing of news articles. | Limited use for non-news sites. Can lead to redundant information if not implemented properly. |
By meticulously addressing sitemap issues and employing effective strategies for generation and maintenance, website owners can significantly improve crawlability, ultimately leading to better search engine rankings and increased organic traffic.
Mobile-First Indexing and Crawlability
Mobile-first indexing is a fundamental shift in how Google and other search engines crawl and index websites. It prioritizes the mobile version of a site, meaning search engines primarily use the mobile site’s content and structure for indexing and ranking purposes. This change necessitates a proactive approach to ensure that websites are not only mobile-friendly but also easily crawlable by search engine bots.
Understanding the implications of this shift is crucial for maintaining and improving a site’s visibility in search results.Mobile-first indexing fundamentally alters the way search engines interact with websites. Previously, search engines relied heavily on the desktop version for indexing. Now, they prioritize the mobile experience, which necessitates a focus on mobile-optimized content and structure. This shift in priority means that websites must be thoroughly optimized for mobile devices to ensure their content is easily accessible and understandable by search engine crawlers.
Fixing common crawlability issues is key for website success. Things like broken links or missing robots.txt files can really hurt your SEO. But, if you want to supercharge your lead generation, consider revitalizing your process using Marketo revitalize your lead generation process using marketo. This can help you capture and nurture leads more effectively, ultimately improving your website’s crawlability by ensuring your content is properly indexed.
Properly implementing these lead generation strategies will ultimately improve the overall website experience, and help ensure search engines can crawl your content.
Mobile-Friendly Website Structure
Ensuring your website is mobile-friendly is paramount. This includes adopting a responsive design that adapts seamlessly to different screen sizes and devices. Using a responsive design allows search engine crawlers to navigate and understand the content on mobile devices without encountering issues. Furthermore, ensuring your website uses a logical, navigable structure that is consistent across both mobile and desktop versions is essential for crawlability.
Testing for Mobile-Friendliness and Crawlability
Testing for mobile-friendliness is critical for ensuring your site is optimized for mobile-first indexing. Google provides a free Mobile-Friendly Test tool to assess your website’s mobile-friendliness. This tool analyzes your site’s responsiveness and identifies areas that need improvement. Beyond the mobile-friendliness test, consider using tools that simulate mobile user behavior to assess crawlability. These tools allow you to identify any issues search engine crawlers might encounter.
Figuring out why your site isn’t getting crawled properly can be a real headache. Common issues include missing robots.txt files or poorly structured sitemaps. Fortunately, there’s a wealth of helpful insights available, like those shared in a recent interview with the Adometry brain trust. This interview dives deep into best practices for website crawlability, offering practical tips to address these issues.
Understanding these techniques will ultimately boost your site’s visibility in search results.
Key Aspects for Mobile-First Crawlability
| Aspect | Explanation | Actions |
|---|---|---|
| Responsive Design | A website with a responsive design automatically adjusts its layout and content to fit different screen sizes, providing a consistent and optimal user experience across various devices. | Implement a responsive design framework (e.g., Bootstrap, Foundation) or use a CMS that supports responsive themes. Regularly test on different devices and screen sizes. |
| Mobile-Optimized Content | Content should be easily readable and navigable on smaller screens. Avoid overly complex layouts, and ensure text is large enough to be easily seen. | Ensure text is easily readable on small screens. Use clear and concise headings. Optimize images for mobile display. |
| Fast Loading Speed | A slow-loading website can negatively impact user experience and search engine rankings. Optimize images, leverage caching mechanisms, and use a content delivery network (CDN) to improve loading times. | Compress images, minify CSS and JavaScript files, and use a CDN. Optimize database queries. |
| Clean URL Structure | Use descriptive and clear URLs that reflect the content of the page. Avoid long, complex URLs. | Use short, -rich URLs. Avoid unnecessary parameters in URLs. |
| Structured Data Markup | Use schema.org vocabulary to mark up your content, helping search engines understand the context and meaning of the data on your pages. | Implement schema markup for products, articles, and other relevant content types. Regularly test markup using validation tools. |
| Crawlable Navigation | Ensure that search engine crawlers can easily navigate all parts of your website, including pages that are not directly linked from the homepage. | Implement a clear sitemap that covers all pages. Ensure that all pages are accessible through links from other pages. |
Crawl Budget Management
Understanding and effectively managing your crawl budget is crucial for ensuring your website is indexed comprehensively and efficiently by search engine crawlers. A well-managed crawl budget allows search engines to prioritize essential pages and avoid overwhelming your server with unnecessary requests. This ultimately translates to improved website performance and visibility in search results.Search engine crawlers, like Googlebot, have a limited capacity to crawl your website within a given timeframe.
This capacity is known as the crawl budget. If the crawl budget is exceeded, crawlers may not index new or updated content, potentially impacting your search engine rankings. Therefore, optimizing your website’s structure and content to efficiently manage this budget is vital.
Strategies for Optimizing Crawl Budget
Effectively managing the crawl budget involves strategically influencing how search engine crawlers interact with your website. This encompasses optimizing website architecture and content to prioritize essential pages and reduce unnecessary crawling.
- Prioritize important pages: Ensure crucial pages, such as product pages, category pages, and blog posts, are easily accessible and crawlable. Use techniques like schema markup to explicitly signal important pages to search engines, helping them prioritize indexing.
- Optimize website structure: A well-structured website with logical navigation facilitates efficient crawling. Employing clean URLs, hierarchical structures, and well-defined sitemaps simplifies the crawling process and directs the crawl budget towards the most relevant content.
- Reduce unnecessary content: Avoid redundant content and optimize for concise, valuable information. Eliminating duplicate content and minimizing the number of low-value pages can free up crawl budget for essential content.
- Improve site speed: Fast loading times positively impact crawl budget. Optimizing images, leveraging browser caching, and minimizing HTTP requests contribute to a faster website, enabling crawlers to process more pages in a given time.
- Use robots.txt effectively: Employ the robots.txt file strategically to guide crawlers, allowing access to important pages and preventing them from accessing irrelevant or unnecessary content. This is critical for directing crawl budget to the most beneficial content.
Monitoring Crawl Budget and Identifying Issues
Monitoring crawl budget and identifying issues requires tracking crawl data and analyzing crawl patterns. Understanding how crawlers interact with your website allows for proactive identification and resolution of potential issues.
- Crawl data analysis: Regularly review crawl data provided by tools like Google Search Console to understand the frequency and depth of crawling. Analyzing crawl patterns reveals potential bottlenecks and crawl budget issues.
- Error tracking: Monitor HTTP status codes returned by your server to identify and resolve server-side errors. Errors can significantly impact crawl budget and prevent proper indexing.
- Sitemap analysis: Review sitemaps to ensure they are up-to-date and accurately reflect the website’s structure. An outdated or incomplete sitemap may lead to ineffective crawl budget management.
- Crawl depth analysis: Assess how deep crawlers are exploring your website. Excessive depth can consume crawl budget, while insufficient depth may mean important pages are missed. Maintaining an optimal crawl depth is essential for efficient indexing.
Crawl Budget Management Strategies
Efficient management of crawl budget requires a strategic approach that prioritizes essential content and optimizes website structure. This table illustrates different strategies for managing crawl budget.
| Strategy | Description | Potential Impact |
|---|---|---|
| Prioritize important pages | Implement schema markup and optimized site structure to signal essential pages to search engines. | Improved indexing of crucial content, leading to better search visibility. |
| Optimize website structure | Employ clean URLs, hierarchical navigation, and well-defined sitemaps to facilitate efficient crawling. | Reduced crawling time and improved resource allocation for valuable content. |
| Reduce unnecessary content | Eliminate duplicate content, minimize low-value pages, and optimize for concise, relevant information. | Free up crawl budget for essential content, leading to more comprehensive indexing. |
| Improve site speed | Optimize images, leverage browser caching, and minimize HTTP requests to enhance page load times. | Increased crawl frequency, improved user experience, and reduced crawl budget consumption. |
| Effective robots.txt usage | Strategically employ robots.txt to guide crawlers, allowing access to crucial pages and preventing access to irrelevant content. | Directed crawl budget towards important content and prevented wasted crawling efforts. |
Ending Remarks
In conclusion, fixing common crawlability issues is a multifaceted process that requires a deep understanding of how search engines operate. By addressing robots.txt, HTTP errors, server problems, content optimization, sitemaps, mobile-first indexing, and crawl budget management, you can dramatically improve your website’s visibility and user experience. This comprehensive guide provides a roadmap for tackling these challenges, empowering you to create a website that is both search engine-friendly and user-centric.