Local Intelligence and Autonomous Agents: Implementing Tool Calling with Gemma 4 and Python
The landscape of the open-weights model ecosystem has undergone a significant transformation with the release of the Gemma 4 model family, a suite of high-performance artificial intelligence models developed by Google. This release marks a pivotal moment for developers and machine learning practitioners who prioritize data privacy and infrastructure control. By offering frontier-level capabilities under a permissive Apache 2.0 license, Google has provided the community with a robust alternative to closed-source, API-dependent models. Central to the utility of the Gemma 4 family is its native support for agentic workflows, specifically tool calling, which allows these models to interact with the real world through external APIs and programmatic functions.
The Evolution of the Gemma Ecosystem
The journey toward Gemma 4 began with Google’s commitment to distilling the research and technology used to create the Gemini models into open-weight versions for the broader developer community. Previous iterations established a baseline for performance in natural language understanding and generation. However, Gemma 4 introduces structural complexities, including a 26B Mixture of Experts (MoE) variant and a parameter-dense 31B model, alongside lightweight, edge-focused versions like the 2B "Edge" (e2b) model.
The transition from static reasoning to dynamic execution represents the most significant leap in this generation. Historically, language models were confined to the data present in their training sets. When queried about real-time events, such as current weather or stock market fluctuations, these models were prone to "hallucinations"—generating plausible but factually incorrect information. Tool calling, or function calling, serves as the architectural remedy to this limitation. It enables the model to recognize when a query requires external data, pause its internal generation, and request the execution of a specific programmatic tool.
Technical Architecture of Tool Calling
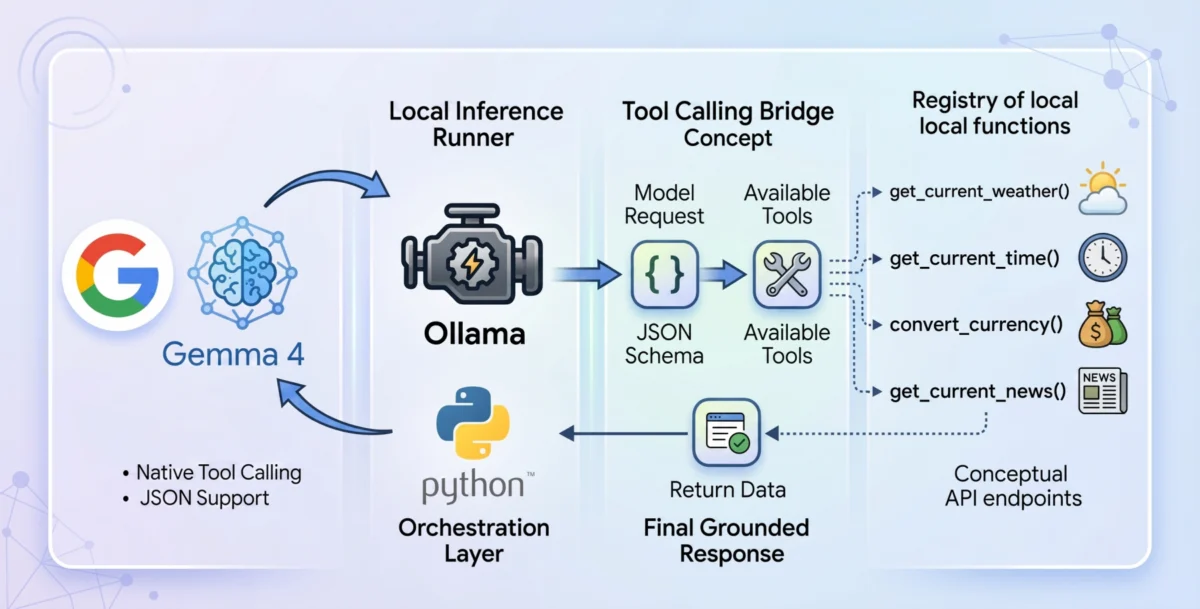
Tool calling is not merely an add-on feature but a foundational shift in how language models process information. In a standard inference cycle, a model generates tokens based on probability. In a tool-calling enabled environment, the model is provided with a "registry" of available tools, defined via JSON schemas. These schemas act as a blueprint, informing the model of the function’s name, its purpose, and the specific parameters it requires.
When a user submits a prompt, the Gemma 4 reasoning engine evaluates whether any available tools are necessary to fulfill the request. If a match is found, the model outputs a structured JSON object rather than a conversational response. This object contains the function name and the arguments required to run it. The host application—in this case, a Python-based environment—intercepts this JSON, executes the corresponding code, and feeds the results back to the model. The model then synthesizes this "live" context to provide an accurate, grounded final answer.
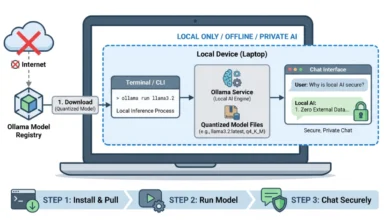
Local Execution via Ollama and the Gemma 4:E2B Model
To achieve a truly privacy-first system, the industry has turned toward local inference runners like Ollama. Ollama simplifies the deployment of complex models on consumer-grade hardware, removing the need for cloud-based intermediaries. For the implementation of a local agent, the gemma4:e2b variant is particularly noteworthy.
The e2b (Edge 2 Billion) model is optimized for mobile devices and Internet of Things (IoT) applications. Despite its small footprint, Google has engineered the model to inherit the multimodal properties and function-calling reliability of its larger counterparts. During inference, the model maintains a near-zero latency execution, which is critical for responsive desktop agents. By running entirely offline, the system eliminates the recurring costs of API tokens and ensures that sensitive user data never leaves the local machine.
Developing a Zero-Dependency Agentic Framework
In building a local tool-calling agent, a "zero-dependency" philosophy is often preferred by engineers seeking maximum portability and security. By relying solely on standard Python libraries such as urllib for web requests and json for data parsing, developers avoid the "dependency hell" often associated with modern AI wrappers.
The architectural flow of such an agent involves several discrete stages:
- The System Prompt: Defining the model’s role and the tools available to it.
- The Initial Request: The model receives the user query and decides whether to invoke a tool.
- The Execution Loop: The Python environment parses the model’s request, runs the local function, and gathers data.
- Context Injection: The data is appended to the conversation history with a "tool" role designation.
- Final Synthesis: The model processes the updated history to generate a natural language response.
Case Study: Implementing Real-Time Weather and Currency Tools
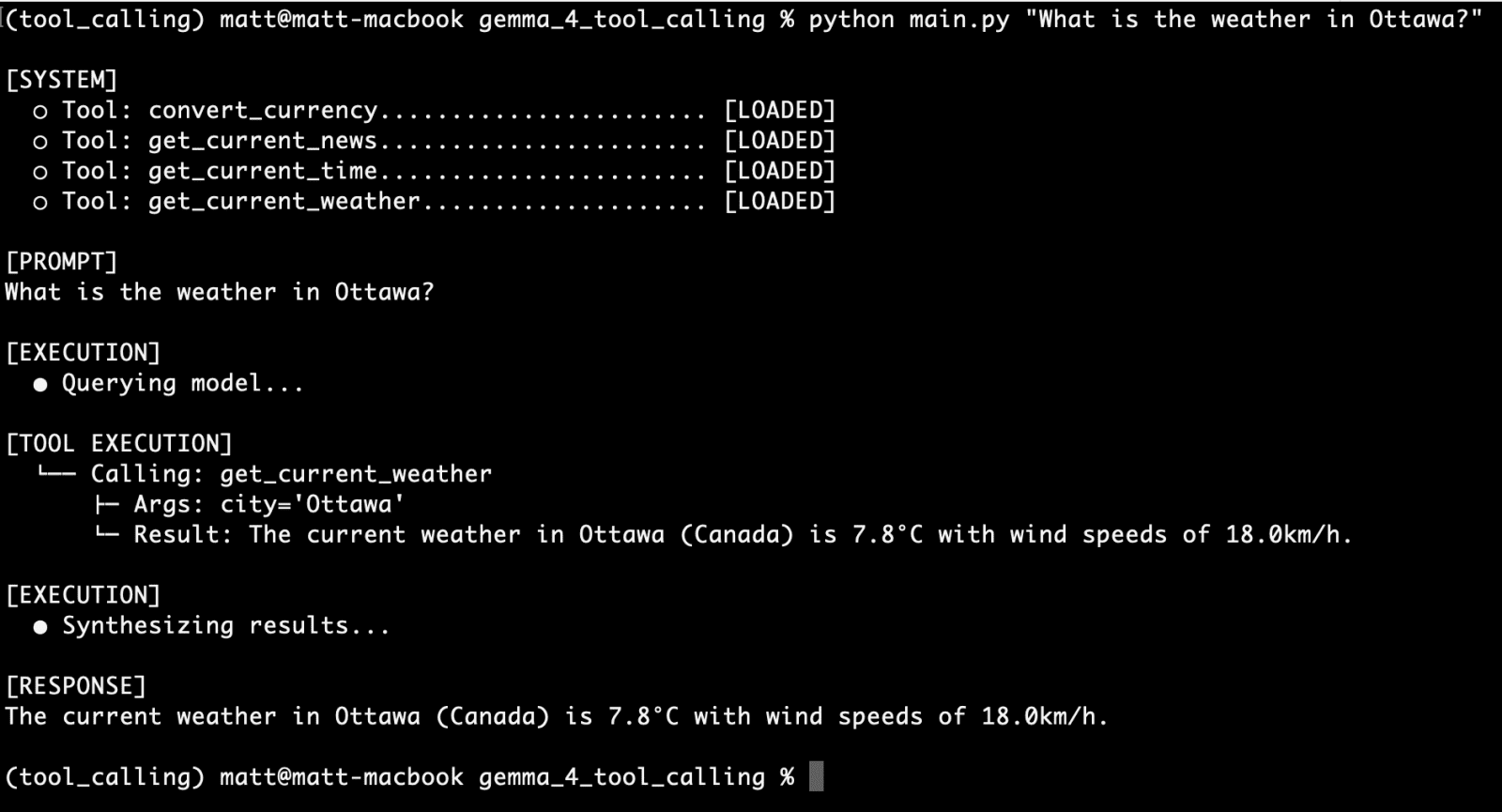
A practical demonstration of Gemma 4’s capabilities involves creating a tool that fetches live weather data. Most weather APIs require precise latitude and longitude coordinates rather than city names. A well-designed Python tool, such as get_current_weather, handles this complexity transparently. It first geocodes the city name into coordinates using an open-source geocoding API and then queries a weather service like Open-Meteo for real-time telemetry.
To make this function visible to the model, it must be mapped to a JSON schema. This schema specifies that the "city" parameter is a required string and allows for optional units like "celsius" or "fahrenheit." This rigid structure is what guides the Gemma 4 weights to generate syntax-perfect calls, a task that was previously difficult for models under 10 billion parameters.
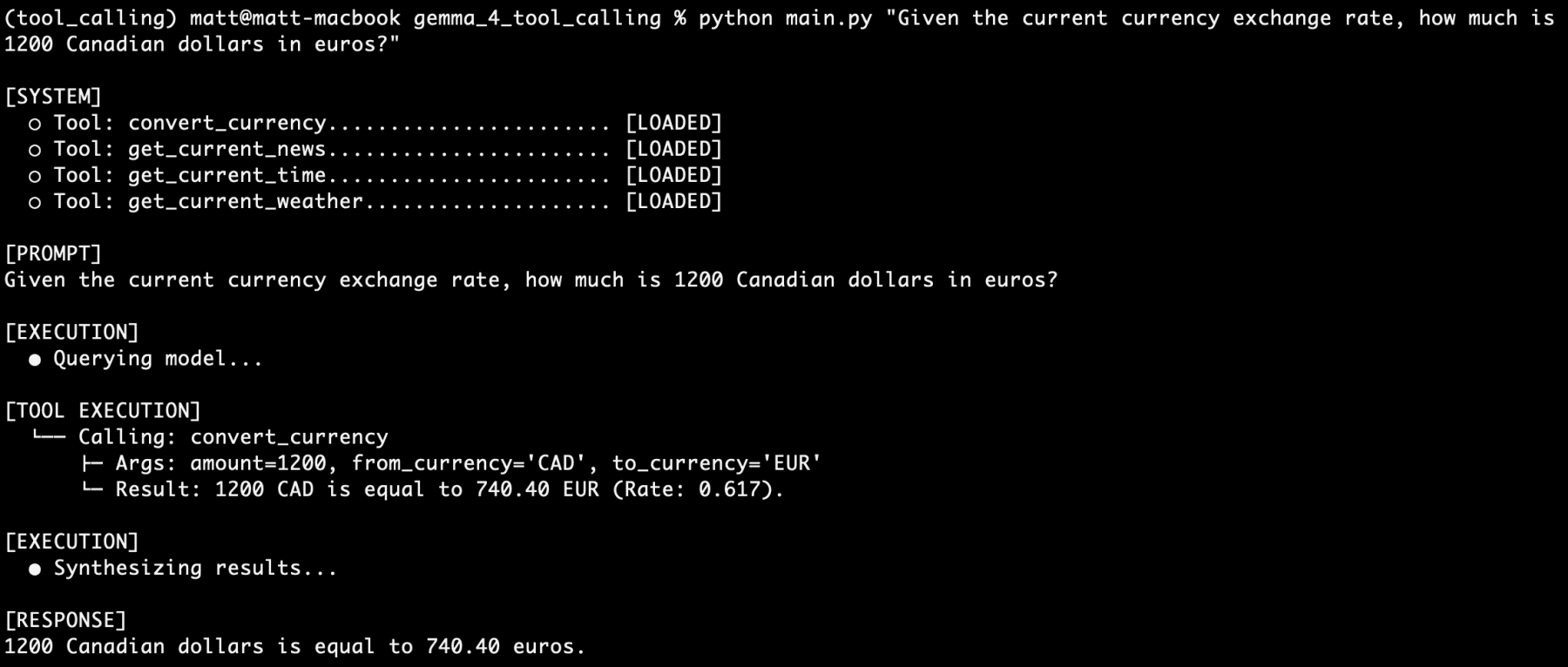
Beyond weather, the agent can be expanded with modular tools for currency conversion, time zone checks, and news retrieval. For instance, a currency conversion tool can query live exchange rates, allowing the agent to perform financial calculations that are grounded in current market reality rather than outdated training data.
Performance Evaluation and Reliability
In rigorous testing of the gemma4:e2b model, the reliability of tool calling has proven to be exceptional for its size class. In scenarios where multiple tools are requested simultaneously—such as asking for the time in Paris, the current weather there, the exchange rate for Euros, and the latest local news—the model successfully orchestrates a sequence of distinct function calls.
This "stacking" of tool requests demonstrates the model’s reasoning depth. It does not simply choose one tool; it identifies all necessary actions, generates the required JSON for each, and waits for the collective results. Observations from extended testing periods indicate that the model maintains high logic consistency, even when user prompts are phrased vaguely. This level of precision suggests that Google’s fine-tuning for structured output has been highly effective in the Gemma 4 series.
Broader Implications for the AI Industry
The democratization of tool-calling capabilities through open-weight models like Gemma 4 has profound implications for several sectors.
1. Data Privacy and Security:
For enterprises handling sensitive proprietary data, the ability to run a functional agent entirely on-premises is a significant security upgrade. It mitigates the risks of data leaks associated with sending information to third-party LLM providers.
2. Cost Efficiency:
By shifting inference to local hardware, organizations can bypass the "pay-per-token" model. For high-volume applications, such as automated data processing or local file management, this results in substantial long-term savings.
3. Edge Computing and IoT:
The efficiency of the 2B parameter model allows for the integration of advanced AI into low-power devices. This paves the way for "smart" appliances and industrial sensors that can reason about their environment and perform complex tasks without a constant internet connection.
4. Developer Innovation:
The Apache 2.0 license encourages a "build-once, deploy-anywhere" approach. Developers can customize the models for niche use cases, such as specialized medical assistants or legal research tools, without worrying about restrictive licensing terms.
Conclusion
The arrival of the Gemma 4 family, supported by local inference engines like Ollama, represents a new chapter in the "Agentic Era" of artificial intelligence. By bridging the gap between static language generation and dynamic programmatic execution, these models transform from simple chatbots into autonomous systems capable of interacting with the digital and physical worlds. As the ecosystem continues to evolve, the focus will likely shift toward further optimizing these small-parameter models to handle even more complex, multi-step reasoning tasks, further narrowing the gap between local and cloud-tier AI performance.






{kind=link}