Building Efficient Long-Context Retrieval-Augmented Generation Systems for the Era of Million-Token Models
The landscape of natural language processing is currently witnessing a fundamental transformation as large language models (LLMs) evolve from restrictive context windows to expansive, million-token capacities. For several years, the standard architecture for Retrieval-Augmented Generation (RAG) was dictated by technical constraints; developers were forced to partition documents into minuscule "chunks" because models like GPT-3.5 or the original Llama iterations could only process between 4,000 and 32,000 tokens at a time. However, the recent release of frontier models such as Google’s Gemini 1.5 Pro and Anthropic’s Claude 3.5 Opus has effectively shattered these barriers, offering context windows that can accommodate entire libraries of technical manuals, legal transcripts, or codebase repositories in a single prompt. While these advancements suggest a future where retrieval might become obsolete, the reality is more complex. High-capacity context windows introduce significant challenges regarding computational latency, escalating API costs, and a phenomenon known as "attention dilution." Consequently, the focus of AI engineering has shifted from simple data retrieval to the sophisticated management of long-context environments.
The Evolution of Context Windows and the RAG Paradigm Shift
To understand the current state of RAG, one must examine the rapid chronological progression of LLM memory. In early 2023, a 16,000-token window was considered state-of-the-art. By late 2023, 128,000 tokens became the enterprise standard with the release of GPT-4 Turbo. By mid-2024, Google announced Gemini 1.5 Pro, capable of handling up to 2 million tokens. This expansion has led to a re-evaluation of the "chunk-and-retrieve" mantra. In the traditional RAG workflow, a system would search for the top three or five most relevant snippets of text and feed them to the model. In the modern era, developers are increasingly feeding the model dozens, or even hundreds, of documents simultaneously.
However, industry benchmarks have revealed that "more" does not always equate to "better." A landmark study titled "Lost in the Middle," conducted by researchers at Stanford, UC Berkeley, and UC San Diego, demonstrated that LLM performance follows a U-shaped curve. Models are highly adept at identifying information at the very beginning or the very end of a prompt, but their accuracy plummets when the relevant facts are buried in the center of a long context. Furthermore, the cost implications are non-trivial. Processing a 1-million-token prompt can cost upwards of $15 to $30 per request depending on the provider, making "brute force" long-context utilization economically unviable for high-volume applications.
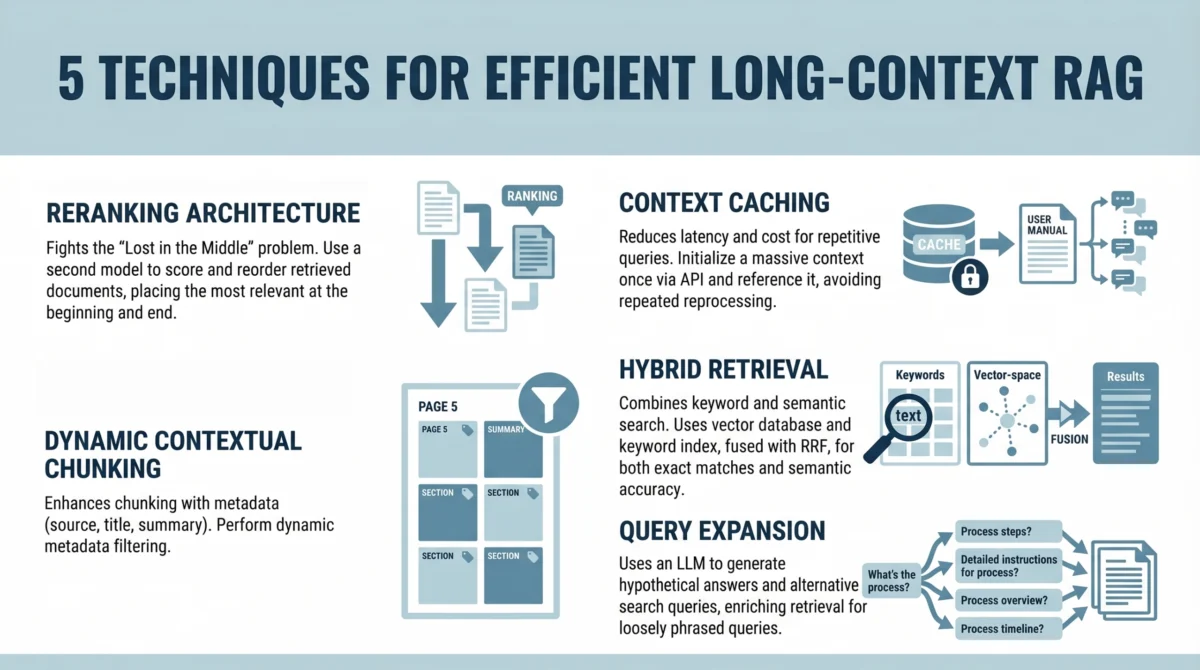
Strategic Reranking: Combating the Lost in the Middle Phenomenon
The first critical technique in modern long-context RAG is the implementation of a reranking architecture. While initial retrieval might pull the top 100 relevant documents using a fast, bi-encoder vector search, these results are often ordered by mathematical similarity rather than actual utility. To combat the attention limitations identified in the "Lost in the Middle" study, developers are now inserting a "cross-encoder" reranking step.
In this workflow, the initial retrieval system identifies a broad set of candidate documents. These candidates are then passed through a more computationally intensive reranking model, such as Cohere’s Rerank or the open-source BGE-Reranker. This model evaluates the specific relationship between the query and each document snippet with higher precision. The most vital innovation here is the strategic placement: once the documents are reranked, the system programmatically places the highest-scoring snippets at the absolute beginning and the absolute end of the prompt. By sandwiching the most critical data in the model’s high-attention zones, developers can maintain high accuracy even when the total context length exceeds 100,000 tokens.
Context Caching: Optimizing Latency and Operational Costs
As context windows grow, the time to first token (TTFT) and the cost per query become the primary bottlenecks for enterprise adoption. Every time a user asks a question about a static set of documents—such as a corporate policy handbook or a software documentation library—the model must re-process the entire context. This is both slow and expensive. To solve this, major providers including Google Cloud (Vertex AI) and Anthropic have introduced Context Caching.
Context caching allows developers to "pre-compute" the hidden states of a large block of text and store them on the provider’s servers for a specific duration. When a new query arrives, the model does not need to re-read the entire context; it simply retrieves the cached state and processes the new query tokens.
Data from early adopters suggests that context caching can reduce costs by up to 90% for repetitive queries and decrease latency by over 80%. For a technical support chatbot that references a 500,000-token manual, the initial cache hit might take several seconds, but every subsequent user interaction feels near-instantaneous. This shift moves RAG from a "stateless" architecture to a "stateful" one, where the knowledge base remains "warm" and ready for interaction.
Precision Engineering through Dynamic Contextual Chunking
While the era of small chunks is ending, the era of "smart" chunks is beginning. Simple character-count partitioning often breaks sentences in half or separates a question from its answer, leading to a loss of semantic integrity. Dynamic contextual chunking utilizes metadata filters and semantic boundaries to ensure that the information provided to the model is coherent.
In this approach, documents are not just split; they are enriched. Each chunk is tagged with metadata such as the document’s title, chapter heading, date of creation, and a brief summary of the surrounding context. When the retrieval system identifies a relevant chunk, it doesn’t just pull that specific 300-word block; it dynamically expands the window to include the preceding and following paragraphs if they share the same metadata tags. This ensures that the LLM receives a complete "thought" rather than a fragmented snippet. Furthermore, metadata filtering allows the system to ignore irrelevant data based on user permissions or timeframes, further reducing the noise that the model’s attention mechanism must filter through.
Hybrid Retrieval: Merging Vector Search with Lexical Accuracy
A common failure point in modern AI systems is the over-reliance on vector (semantic) search. While vector embeddings are excellent at understanding that "feline" is related to "cat," they often struggle with specific technical identifiers, part numbers, or unique legal terminology. In a long-context environment, this can lead to the model retrieving "similar" documents that do not actually contain the specific answer required.
To address this, high-performance RAG systems are increasingly adopting Hybrid Retrieval. This combines traditional keyword search (BM25) with modern vector search. By using an algorithm known as Reciprocal Rank Fusion (RRF), the system merges the results from both methods into a single, optimized list.
The impact of hybrid search is most visible in technical industries. For instance, if an engineer searches for a specific error code like "0x8004210B," a vector search might return general troubleshooting documents for email errors, whereas a keyword search will pinpoint the exact page in the manual where that code is defined. By combining these methods, the RAG system ensures that it captures both the nuanced meaning of a query and the literal requirements of the user.
Query Expansion and the Summarize-Then-Retrieve Workflow
The final frontier in efficient RAG is bridging the gap between how users ask questions and how documents are written. A user might ask, "What do I do if the fire alarm goes off?" while the relevant document is titled "Emergency Egress and Auditory Alert Protocols." A standard retrieval system might fail to find a high-similarity match between these two phrases.
Query expansion, specifically the "Summarize-Then-Retrieve" or "Hypothetical Document Embeddings" (HyDE) technique, uses a lightweight, fast LLM to generate multiple versions of the user’s query before the retrieval starts. The system might generate hypothetical answers or alternative phrasings such as "evacuation procedures" or "fire safety instructions." By searching for these expanded terms simultaneously, the system significantly increases the likelihood of finding the correct information within a massive dataset. This is particularly effective for "inferential" queries—questions where the answer isn’t explicitly stated but must be pieced together from multiple sections of the context.
Industry Implications and the Path Forward
The transition toward long-context RAG represents a shift from "finding the needle in the haystack" to "organizing the haystack so the needle is always on top." Industry leaders have reacted with cautious optimism. OpenAI’s technical leadership has noted that while context windows will continue to grow, the "intelligence-per-token" remains the most valuable metric. Meanwhile, open-source advocates argue that these long-context techniques are essential for democratizing AI, as they allow smaller, more efficient models to compete with giants by providing them with better-organized data.
The broader implications for enterprise AI are profound. Companies no longer need to spend months fine-tuning models on their internal data; they can instead build sophisticated RAG pipelines that provide the model with the necessary "short-term memory" to solve complex tasks. However, the responsibility now lies with developers to implement the five techniques outlined above. Without reranking, caching, and hybrid search, the million-token context window risks becoming a "black hole" of high costs and diluted accuracy.
As we look toward 2025, the goal of RAG is not simply to provide more context, but to provide the right context in the right order. By respecting the limitations of human-designed attention mechanisms and leveraging the efficiencies of modern caching, organizations can build AI systems that are both incredibly knowledgeable and economically sustainable. The era of million-token models is not the end of RAG; it is the beginning of its most sophisticated chapter.








{kind=link}