reducing
-
Artificial Intelligence in Finance
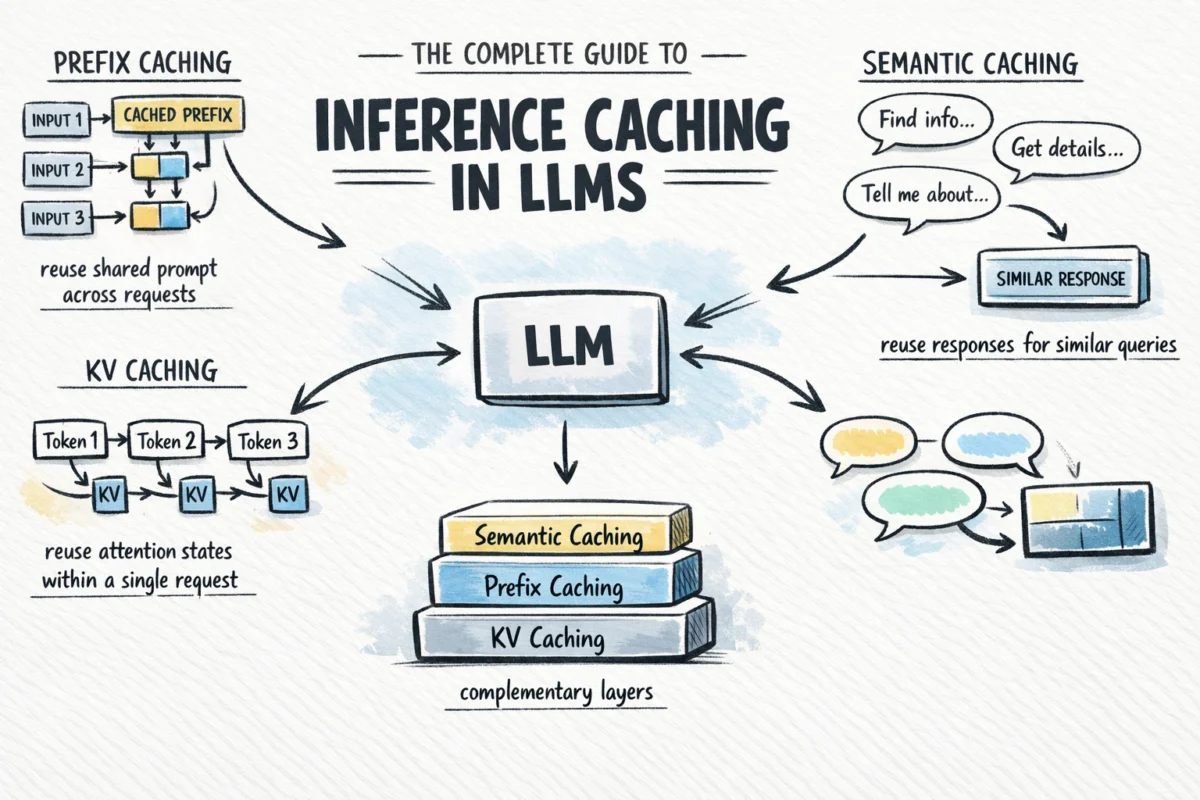
The Complete Guide to Inference Caching in Large Language Models: Strategies for Reducing Latency and Cost in AI Production
The rapid proliferation of large language models (LLMs) across enterprise applications has brought the twin challenges of operational cost and…
Read More »
