TurboQuant Achieves Near Optimal KV Cache Compression with Minimal Accuracy Loss in Large Language Models
The evolution of generative artificial intelligence has been fundamentally driven by the Transformer architecture, a design where the attention mechanism serves as the primary cognitive engine. This mechanism allows Large Language Models (LLMs) to discern relationships between different tokens in a sequence, enabling the sophisticated reasoning and context-awareness that define modern AI. At the heart of this process are three mathematical components: the Query (Q), Key (K), and Value (V) matrices. By calculating the dot product between the Query and the Key, a model determines the degree of focus each token should accord to others, effectively mapping the internal relevance of a given text.
However, the computational brilliance of the attention mechanism carries a significant operational burden. During the inference phase—when a model generates text—the system must predict tokens one by one. For every new token generated, the Key and Value matrices for all preceding tokens are traditionally recalculated. In a scenario where a model has already processed 90 tokens and is predicting the 91st, it must re-evaluate the KV matrices for the initial 90 tokens. This iterative redundancy represents a substantial waste of computational cycles and energy, leading researchers to seek more efficient alternatives.
The Rise of KV Caching and the Memory Wall
To address the inefficiencies of redundant computation, the industry transitioned to a technique known as KV caching. The logic behind KV caching is straightforward: instead of recomputing the K and V matrices at every step, the model stores these matrices in Video Random Access Memory (VRAM) after their initial calculation. This allows the system to reuse existing data during inference, drastically reducing latency and improving the speed of response. Consequently, KV caching has become a standard feature in almost every major LLM deployment, from open-source models like Llama to proprietary systems like GPT-4.

While KV caching solved the latency problem, it introduced a new crisis: memory overhead. Storing these matrices requires significant VRAM, often consuming an additional 20% to 30% of the total memory budget. For "mega-LLMs" featuring hundreds of billions of parameters, this overhead makes it increasingly difficult to host models on standard hardware. Furthermore, the memory requirement is not static; it scales linearly with the length of the context and the number of concurrent users. As developers push for longer context windows—expanding from 8,000 tokens to over a million—the KV cache can eventually exceed the size of the model itself.
Chronology of Optimization Efforts
The pursuit of KV cache efficiency has seen several milestone developments over the last three years. In early 2023, researchers introduced Grouped-Query Attention (GQA), which reduced the number of Key and Value heads relative to Query heads, thereby shrinking the cache size. Later that year, the "PagedAttention" algorithm, popularized by the vLLM framework, revolutionized memory management by treating KV cache memory like virtual memory in operating systems, reducing fragmentation.
Despite these advances, the industry remained at a crossroads. Standard quantization techniques—reducing the precision of the KV cache from 16-bit floating point to 4-bit or 8-bit integers—succeeded in reducing memory footprints but often at the cost of model accuracy. Lowering the bit-depth frequently resulted in "perceptual loss," where the model’s reasoning capabilities or linguistic nuances were degraded. This trade-off persisted until the emergence of TurboQuant, a new framework developed by researchers at Google, which claims to achieve high compression rates while maintaining near-zero accuracy loss.
Technical Architecture of TurboQuant
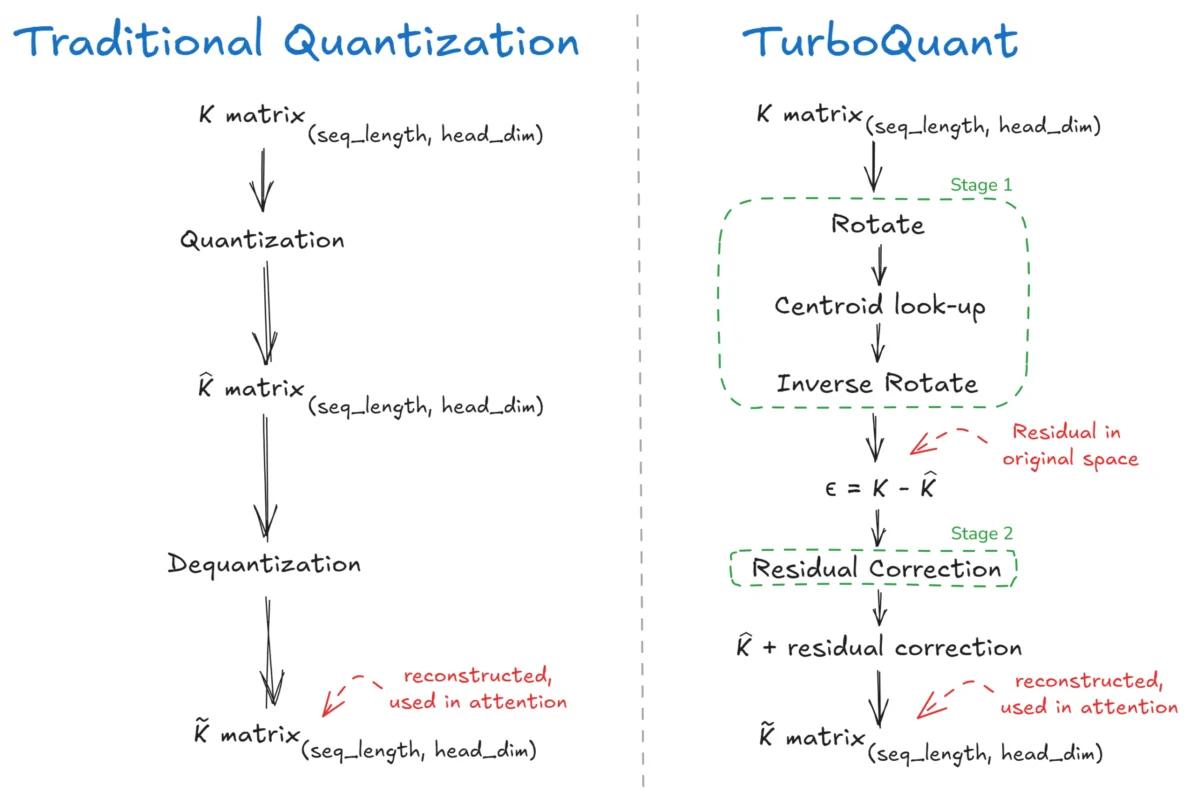
TurboQuant represents a departure from traditional quantization by utilizing a two-stage "online" vector quantization pipeline. Unlike "offline" methods that require pre-processing the entire model, TurboQuant operates dynamically during the inference process. The system is divided into two primary phases: PolarQuant and Residual Correction.

Stage 1: PolarQuant and the Power of Rotation
The first stage, PolarQuant, addresses a primary flaw in traditional quantization: the handling of outliers. In attention mechanisms, Key vectors often contain "spiky" data—specific dimensions with much higher values than others. When a standard quantizer encounters a spike, it must stretch its limited numerical levels to accommodate that high value, which causes the smaller, more nuanced values in the vector to be rounded to zero.
To solve this, PolarQuant applies a randomized orthogonal rotation matrix to the vector. This "spinning" of the vector in high-dimensional space redistributes the energy of the outlier across all coordinates, creating a smooth, isotropic distribution. Following this rotation, the vector follows a predictable distribution, allowing the system to use Lloyd-Max Quantization. Lloyd-Max is an optimization algorithm that places quantization "centroids" in the most statistically effective locations to minimize mean squared error. Because the rotation ensures the data follows a known distribution (specifically a Beta distribution), TurboQuant can use precomputed codebooks, eliminating the need for expensive calculations during inference.
Stage 2: Residual Correction via QJL
The second stage of TurboQuant is what sets it apart from previous compression attempts. While PolarQuant compresses the bulk of the data, it still leaves behind a small amount of error, or "residual." Traditional methods simply discard this error. TurboQuant, however, applies a Residual Correction using the Quantized Johnson-Lindenstrauss (QJL) Transform.
This stage does not attempt to store the full residual. Instead, it asks a series of "binary" questions about the residual data—essentially determining if a dimension is leaning positive or negative. By storing these sign bits (+1 or -1) and the L2 norm (the overall magnitude) of the residual, the system can reconstruct the lost information with remarkable fidelity. The final output is a combination of the dequantized PolarQuant matrix and the reconstructed QJL residual, resulting in a representation that is mathematically near-optimal.

Supporting Data and Performance Benchmarks
The effectiveness of TurboQuant is evidenced by its compression statistics and its impact on model performance. According to the original research paper, TurboQuant delivers a KV cache compression rate of 4.5x to 5x. In practical terms, this means that data originally requiring 16 bits of precision can be stored using an effective rate of only 2.5 to 3.5 bits per channel.
Key performance metrics identified in the study include:
- Accuracy Retention: The authors report "near-zero" accuracy loss across standard benchmarks, a claim backed by the mathematical proof that the solution sits at the "theoretical optimum" for vector quantization.
- Latency Efficiency: Because the Lloyd-Max codebooks are precomputed and the rotation matrices are orthogonal, the computational overhead added by the quantization process is negligible compared to the time saved by reducing VRAM bottlenecking.
- Hardware Flexibility: By reducing the KV cache size by nearly 80%, TurboQuant allows larger models to run on consumer-grade hardware or enables significantly higher throughput (more concurrent users) on enterprise-grade H100 or A100 GPUs.
Official Responses and Industry Implications
While Google researchers have spearheaded the development of TurboQuant, the broader AI community has reacted with cautious optimism. AI infrastructure engineers have noted that the "online" nature of TurboQuant makes it particularly attractive for cloud service providers who need to maximize GPU utility without retraining models.
In statements regarding the research, the authors emphasize that TurboQuant is designed to be "plug-and-play." Unlike Grouped-Query Attention (GQA), which requires the model to be trained with a specific architecture from the start, TurboQuant can be applied to existing pre-trained models. This versatility suggests that the framework could soon be integrated into popular inference engines like Hugging Face’s Text Generation Inference (TGI) or NVIDIA’s TensorRT-LLM.

Broader Impact on the AI Landscape
The implications of TurboQuant extend beyond mere memory savings. As the industry moves toward "Agentic AI"—systems that can maintain long-running conversations and process massive documents—the ability to manage long-context memory is paramount. By solving the KV cache bottleneck, TurboQuant paves the way for models that can "remember" hundreds of thousands of words without requiring a proportional increase in hardware investment.
Furthermore, this technology has significant implications for edge computing. Small Language Models (SLMs) designed to run on laptops or smartphones are often limited by the available RAM. TurboQuant’s ability to compress the memory footprint of these models could accelerate the deployment of high-performance, private AI on personal devices.
The development of TurboQuant signals a shift in AI research. For years, the primary solution to scaling LLMs was to build larger chips with more VRAM. TurboQuant suggests that the next frontier of AI performance lies not just in hardware expansion, but in the sophisticated mathematical refinement of how data is handled. As context windows continue to grow, the industry will likely rely on these "intelligent compression" techniques to keep the promise of generative AI economically and technically viable. Whether TurboQuant becomes the definitive standard or serves as a precursor to even more advanced methods, it has successfully demonstrated that the "VRAM tax" is not an inevitability, but a challenge that can be overcome through algorithmic innovation.







{kind=link}