The Complete Guide to Inference Caching in Large Language Models: Strategies for Reducing Latency and Cost in AI Production
The rapid proliferation of large language models (LLMs) across enterprise applications has brought the twin challenges of operational cost and inference latency to the forefront of artificial intelligence engineering. As organizations move from experimental prototypes to high-volume production systems, the inefficiencies of recomputing the same mathematical operations for repetitive queries have become an economic and technical bottleneck. Inference caching has emerged as the primary architectural solution to these challenges, offering a sophisticated methodology for storing and reusing the results of expensive LLM computations. By implementing caching at various layers of the inference stack, developers can achieve significant reductions in token expenditure and dramatic improvements in response times, often reducing costs by as much as 50 to 90 percent for specific workloads.
The Evolution of LLM Efficiency: A Contextual Background
To understand the necessity of inference caching, one must look at the fundamental architecture of the Transformer model, introduced by Google researchers in the seminal 2017 paper "Attention Is All You Need." LLMs operate on a principle of self-attention, where every token in a sequence must be evaluated in the context of every preceding token. This process is autoregressive, meaning the model generates one token at a time, feeding the entire previous sequence back into the system to predict the next word.
As context windows have expanded—from the 4,000 tokens of early GPT-3.5 models to the 2-million-token capacity of Google’s Gemini 1.5 Pro—the computational burden has scaled quadratically or linearly depending on the specific optimization used. In a production environment, this means that a system prompt containing 10,000 words of legal documentation or technical specifications is reprocessed from scratch every time a user asks a simple question. This redundancy is the core inefficiency that inference caching seeks to eliminate.
The Three Pillars of Inference Caching
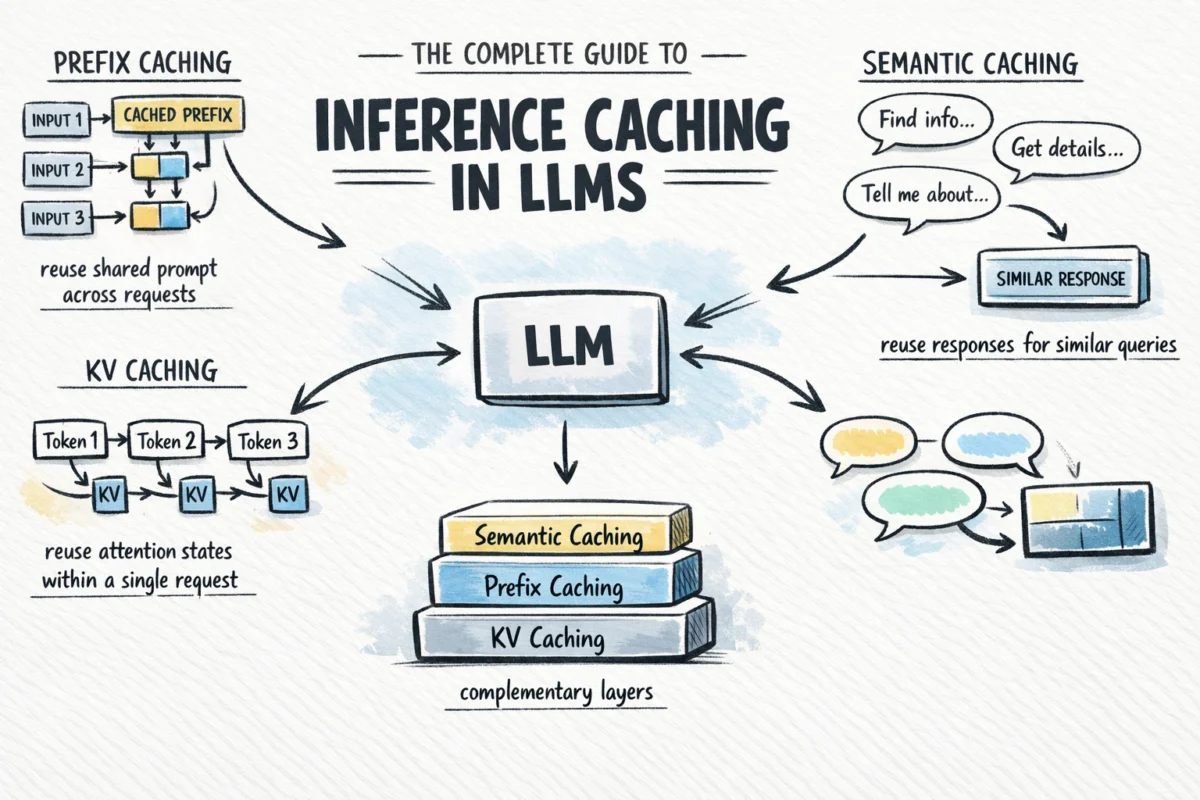
Inference caching is not a monolithic technology but a tiered strategy comprising three distinct layers: KV Caching, Prefix Caching, and Semantic Caching. Each operates at a different stage of the request lifecycle and offers varying degrees of optimization.
1. KV Caching: The Foundation of Token Generation
Key-Value (KV) caching is an optimization internal to the model’s inference engine. During the attention mechanism’s execution, the model generates "Key" and "Value" vectors for each token. These vectors represent the token’s relationship to other parts of the sequence. In a standard autoregressive generation process, generating the 101st token would theoretically require recomputing the math for the previous 100 tokens.
KV caching prevents this by storing these vectors in the GPU’s High Bandwidth Memory (HBM). When the model moves to the next token, it simply retrieves the stored KV pairs for the previous tokens and only performs new calculations for the most recent addition.
Industry Impact:
KV caching is now a universal standard. Frameworks like vLLM have further optimized this through "PagedAttention," which manages KV cache memory similarly to how operating systems manage virtual memory, reducing fragmentation and allowing for higher throughput. Without KV caching, modern real-time AI chat interfaces would be functionally impossible due to the compounding latency of each new word generated.
2. Prefix Caching: Optimizing Shared Contexts
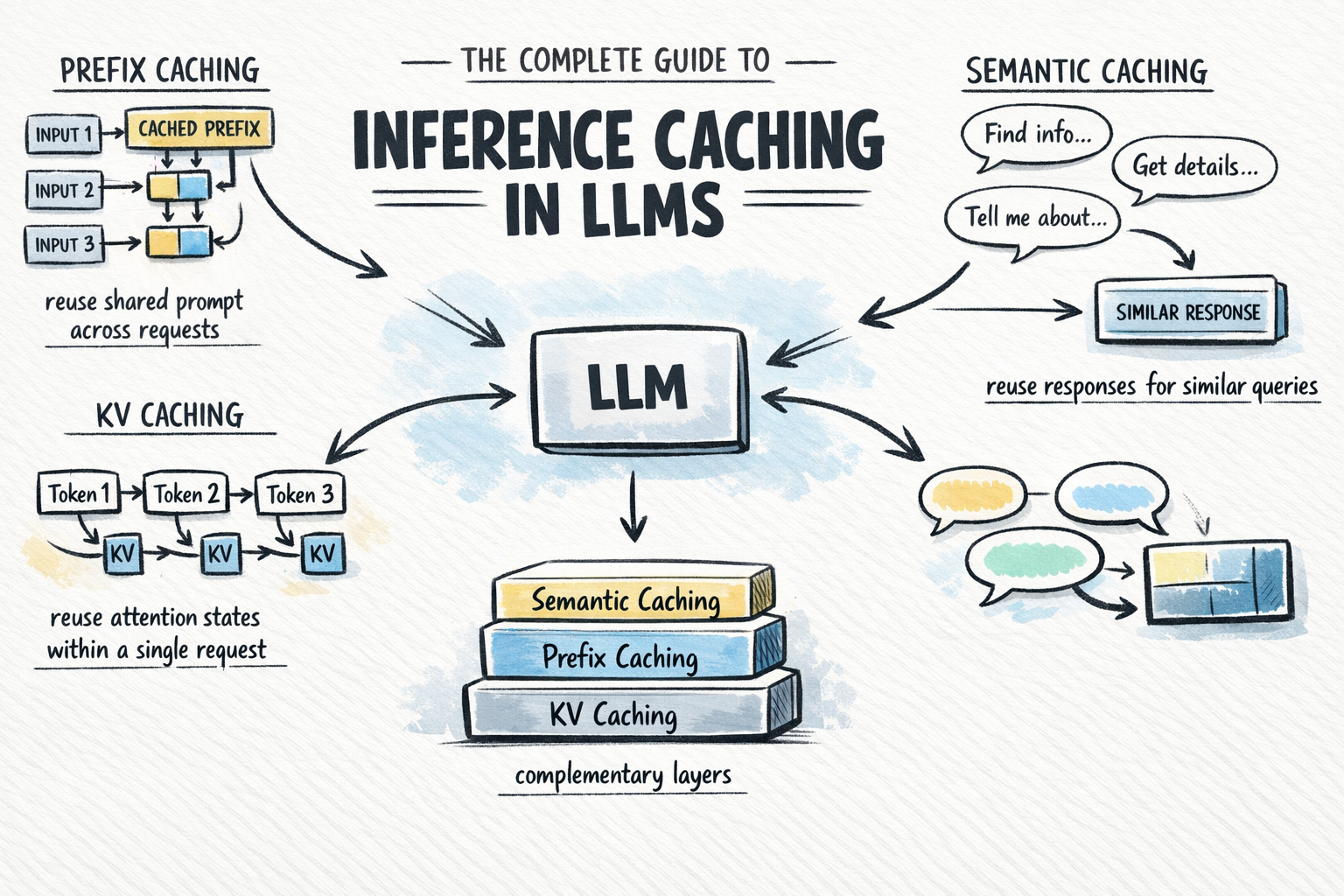
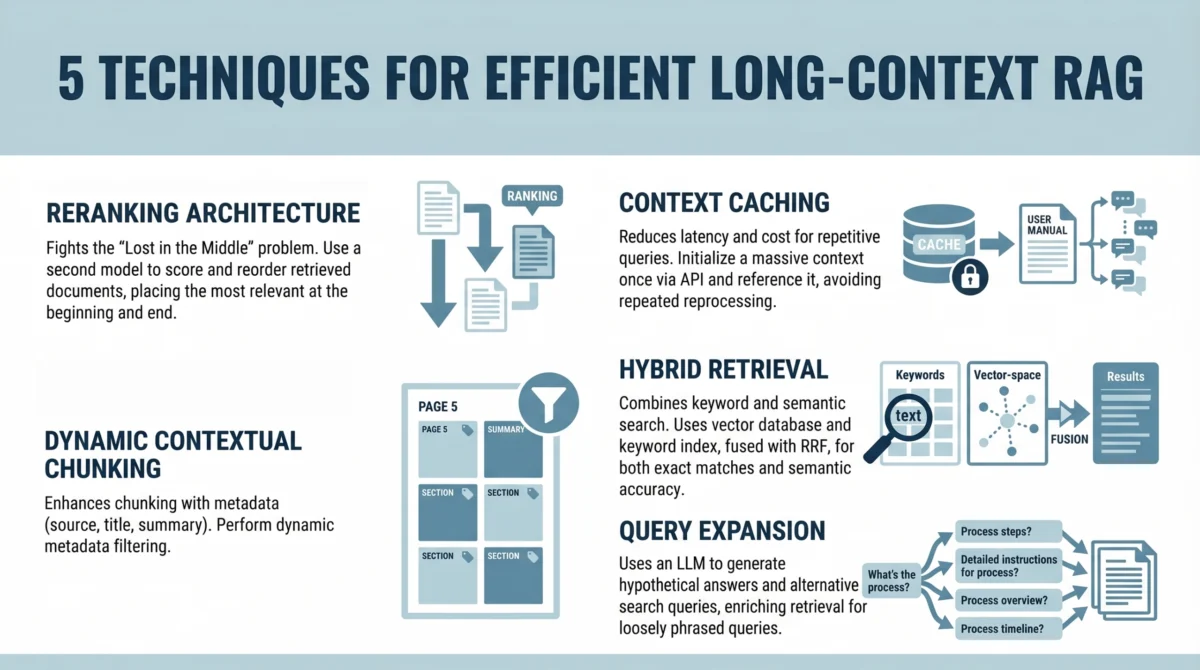
While KV caching works within a single request, Prefix Caching (often marketed as Prompt Caching) allows the model to reuse KV states across different requests from different users. This is particularly potent for applications that utilize long system instructions, extensive "few-shot" examples, or large retrieved documents in a Retrieval-Augmented Generation (RAG) pipeline.
If a developer provides a 5,000-token reference manual as part of the prompt, and 1,000 users ask different questions about that manual, the model traditionally "reads" those 5,000 tokens 1,000 times. With prefix caching, the KV states for those 5,000 tokens are computed once and stored. Subsequent requests that lead with the exact same 5,000 tokens skip the initial processing phase entirely.
The Byte-for-Byte Requirement:
A critical technical constraint of prefix caching is its sensitivity. The cached prefix must be an exact, bit-perfect match. Even a single additional space, a change in a timestamp, or a variation in JSON key ordering will result in a "cache miss," forcing the engine to recompute the entire prompt at full cost.
3. Semantic Caching: Meaning-Based Retrieval
Semantic caching represents the highest level of the stack. Unlike the previous two methods, which still involve the LLM to some degree, semantic caching can bypass the LLM entirely. It works by storing the final output of a query and retrieving it when a "semantically similar" query is received.
For example, if User A asks, "How do I reset my password?" and User B asks, "What is the procedure for a password reset?", a semantic cache recognizes that these intents are identical. It uses embedding models to convert the text into numerical vectors and performs a similarity search (usually via Cosine Similarity) in a vector database. If the similarity score exceeds a predefined threshold (e.g., 0.95), the system returns the cached answer from User A to User B.
Chronology of Adoption and Provider Milestones
The transition of caching from a niche optimization to a standard API feature has occurred rapidly over the last 24 months:
- Late 2023: Open-source frameworks like vLLM and SGLang introduced automated prefix caching, allowing developers hosting their own models on A100/H100 GPUs to slash costs.
- August 2024: Anthropic officially launched Prompt Caching for its Claude 3.5 Sonnet and Haiku models. Anthropic’s implementation introduced a tiered pricing model where cached tokens are up to 90% cheaper than base tokens.
- October 2024: OpenAI announced the integration of Prompt Caching for GPT-4o. Unlike Anthropic’s manual "opt-in" markers, OpenAI’s system automatically detects prefixes longer than 1,024 tokens and applies a discount, typically offering a 50% price reduction for cached content.
- Late 2024: Google Gemini expanded its "Context Caching" feature, allowing for massive contexts (up to the full context window) to be cached for a specific duration, with a storage fee applied per hour.
Data-Driven Analysis of Benefits
The implementation of inference caching yields measurable improvements in two primary metrics: Time to First Token (TTFT) and Cost Per Request.
Impact on Latency
In long-context scenarios, the "prefill" stage (processing the input prompt) is often the slowest part of the process. For a 30,000-token prompt, prefix caching can reduce TTFT from several seconds to a few hundred milliseconds. In customer service applications, this difference is the boundary between a tool that feels "human-like" and one that feels "broken."
Economic Efficiency
According to pricing data from leading providers:
- Anthropic: Standard input tokens for Claude 3.5 Sonnet cost $3.00 per million. Cached tokens cost $0.30 per million. For a company processing 100 million tokens daily with a 80% cache hit rate, the daily savings exceed $200,000.
- OpenAI: GPT-4o offers a 50% discount on cached tokens. While less aggressive than Anthropic, the "automatic" nature of the cache ensures that even unoptimized applications see immediate ROI.
Strategic Implementation: A Decision Framework
For AI architects, choosing the right caching strategy depends on the specific architecture of the application.
| Application Type | Recommended Strategy | Rationale |
|---|---|---|
| General Purpose Chat | KV Caching | Essential for basic responsiveness. |
| Enterprise RAG | Prefix Caching | Large knowledge bases stay static across user queries. |
| Agentic Workflows | Prefix Caching | Agents often carry long histories of "state" that are repetitive. |
| High-Volume FAQ Bots | Semantic Caching | Users frequently ask the same questions in slightly different ways. |
Critical Challenges and Risks
Despite the advantages, inference caching introduces new complexities into the AI lifecycle.
1. Stale Information:
Semantic caching, in particular, carries the risk of serving outdated information. If a company changes its return policy but the semantic cache still holds the old policy, the bot will confidently provide incorrect data. Developers must implement rigorous Time-to-Live (TTL) settings and manual cache invalidation protocols.
2. Privacy and Security:
Caching sensitive data requires careful "tenant isolation." If a cache is shared across multiple users, there is a risk of a "cache poisoning" or data leakage, where User B receives a response intended for User A because their queries were semantically similar.
3. The "Cold Start" Problem:
Caches provide no benefit for the first request. In low-traffic applications, the overhead of maintaining a semantic cache (vector database costs and embedding latency) may actually outweigh the benefits of the model hit.
The Future of Inference Optimization
Industry analysts expect inference caching to evolve toward "Dynamic Caching," where models can intelligently decide which parts of their internal state are worth keeping based on global usage patterns. Furthermore, as multi-modal models (handling images and video) become the norm, the caching of visual features will become the next frontier. A video-processing AI, for instance, could cache the background of a scene to focus computation only on moving subjects across different user queries.
In conclusion, inference caching has transitioned from an advanced optimization for specialized engineers to a fundamental requirement for any scalable AI strategy. By understanding the interplay between KV, prefix, and semantic layers, organizations can transform LLMs from expensive, high-latency experiments into efficient, cost-effective enterprise assets. As the "AI gold rush" moves into a phase of fiscal responsibility and performance optimization, caching stands as the most effective lever for sustainable growth.






{kind=link}